
Auto Arima dalam Python: Simple dan Akurat
Auto Arima: Arima dan sarima sudah lengkap dijelaskan dalam blog ini. Namun, metode yang dijelaskan tetap memiliki kekurangan karena masih mengandalkan analisis yang bersifat visual. Analisis yang bersifat visual diantaranya adalah menentukan apakah plot time series bersifat stasioner ataukah tidak. Tidak ada yang salah dengan metode tersebut. Tapi para akademis menginginkan yang pasti. Mereka lebih menyukai keputusan itu diambil secara statistik. Hal ini sesuai dengan artikel saya bahwa kuantitatif lebih baik dari kualitatif.
Contoh kedua adalah menganalisis bentuk autokorelasi dan partial autokorelasi yang bersifat dying down ataukah cut off. Metode ini bisa diperdebatkan karena standar yang digunakan adalah visual yang bergantung kepada persepsi seseorang.
Artikel ini berusaha menjelaskan arima dengan uji statistik yang akurat. Perhitungan stasioneritasnya menggunakan uji augmented dickey fuller yang secara gambalang memberikan H0 dan H1 kemudian batasan bagaimana menolak ataupun menerima H1. Pengolahan arima kali ini menggunakan python, sebuah alat analisis yang free dan bisa digunakan tanpa harus bermasalah dengan lisensi. Bagi anda yang belum tau bagaimana menginstal python, silahkan simak artikel install dan menjalankan python di windows. Saya sudah merangkumnya bagi pemula dan semoga bisa diikuti dengan baik.
Module yang digunakan dalam auto arima
Data latihan yang digunakan kali ini bisa didownload pada link dibawah ini. Anda tidak perlu repot membayar dan cukup membaca artikel ini insha allah sudah bisa memahami. Hanya saja. Script yang saya tampilkan dalam bentuk gambar. Jika anda ingin dimudahkan, maka silahkan memberikan sedikit sponsor artikel ini untuk mendapatkan passwordnya.
Latihan auto arima
Setelah mendownload, ekstrak folder tersebut di folder tempat python terinstall. Secara default python jupyter akan berada di C/users/user. Silahkan simak cara instal seperti yang sudah saya sebutkan diatas untuk lebih jelasnya.
Kemudian jalankan jupyter notebook melalui cmd atau command promt di windows. Namun, sebelum itu, kita perlu menginstall module atau paket yang akan digunakan dalam python. Paket itu adalah pandas, matplotlib, seaborn, statsmodels, pmdarima. Cara menginstallnya adalah mengetikkan di cmd:
pip install pandas , tekan enter kemudian tunggu hingga proses selesai. Pastikan koneksi internet terjaga. Lakukan itu untuk semua paket (sampai dengan pmdarima). Khusus pmdarima, saya mengalami kendala saat menggunakan python 3.11 (terbaru saat artikel ini ditulis). Sehingga saya menggunakan python versi 3.8.

Setelah module semua diinstall, silahkan masuk ke jupyter notebook dan buka file arima python yang diekstrak tadi. Saya mengekstraknya di folder latihan seperti penjelasan pada cara install python.
Langkah auto arima dalam python
Langkah pada artikel ini tidak baku. Karena python adalah free source, jadi syntax ini disusun berdasarkan urutan pengolahan arima yang umum saja.
Import data
Langkah pertama adalah mengimport data. data yang disediakan sudah include dalam folder. Jika anda kurang memahami python, jangan ganti nama field atau nama kolom karena itu akan memengaruhi proses pengolahan, termasuk juga nama file jangan diubah. Silahkan saja anda edit data yang akan di forecast mulai dari row dua hingga kebawah.

Tampilan data csv yang tersedia terdiri dari dua kolom. Kolom pertama date yang berisi keterangan nomor data, dan juga “data” adalah kolom yang berisi data untuk forecast. Data tidak boleh terisi hanya satu kolom. Jika anda hanya memiliki 20 data, maka data kebawah didelete (delete row).
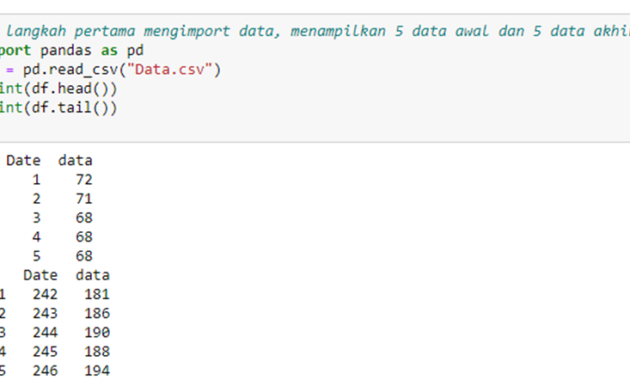
Line pertama dalam python adalah seperti gambar diatas. Pada syntax ini berfungsi untuk memanggil atau mengupload data yang terdapat dalam file Data.csv. kemudian untuk konfirmasi akan dimunculkan 5 data pertama dan 5 data terakhir. Ketik syntax diatas kemudian klik run pada menu python, maka akan muncul tabel dibawahnya.
Membuat time series plot
Setelah datanya terimport maka selanjutnya adalah membuat time series plot untuk melihat sebaran data menurut waktunya.

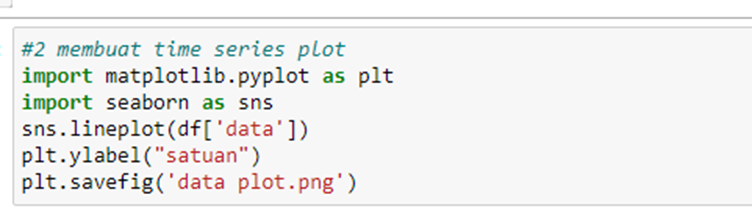

Menambahkan garis rata-rata dan standar error
Fungsi menambahkan garis rata-rata dan standar error untuk mengetahui berapa simpangan yang terjadi dan kira kira jika kita akan membuat model, akan menimbulkan simpangan yang besar atau kecil. Syntaxnya adalah sebagai berikut:


Hasil akan tercantum dalam python jupyter dan akan tersave secara otomatis dengan nama file “rata-rata std deviasi.png”. Dan hasilnya adalah sebagai berikut:

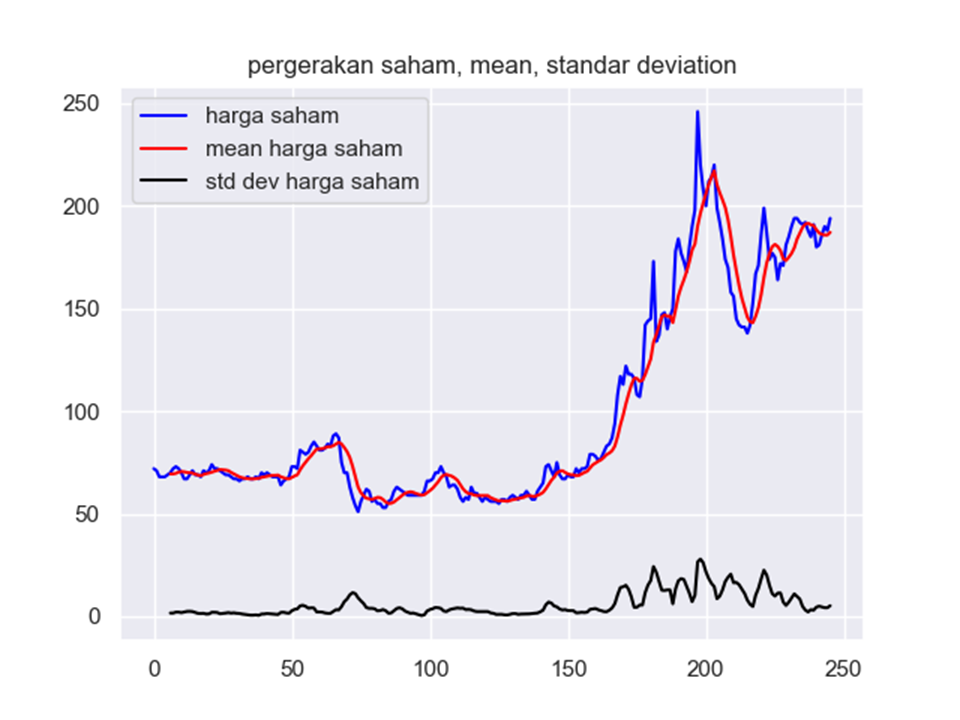
Sedikit memberi analisis, bahwa grafik diatas memiliki banyak simpangan terutama pada n ke 150 hingga 250. Hal ini ditandai dengan fluktuasi std deviasi. Ini mengindikasikan bahwa model ini sebenarnya memiliki musiman. Analisis kedua grafik ini jelas memiliki trend dan tidak stasioner. Karena memiliki trend positif yang signifikan. Mari kita buktikan secara uji statistik melalui uji ADF berikut:
Memeriksa stasioner data
Pemeriksaan data stasioner atau tidak menggunakan uji Augmented dickey fuller dengan keterangan:
H0 : data tidak stasioner
H1 : data telah stasioner
Dikatakan tolak H0 atau data stasioner jika p value yang dihasilkan lebih kecil dari 5 persen.
Adapun syntax yang diketik adalah:


Karena ada syntax yang terpotong, saya copykan sintax dibawah ini:
output_df = pd.DataFrame({"Values":[adft[0],adft[1],adft[2],adft[3], adft[4]['1%'], adft[4]['5%'], adft[4]['10%']] , "Metric":["Test Statistics","p-value","No. of lags used","Number of observations used", "critical value (1%)", "critical value (5%)", "critical value (10%)"]})
print(output_df)Hasil yang diperoleh bahwa p value 0.91 artinya data tidak stasioner atau terima H0. Nah, uniknya dalam proses ini kita tidak perlu repot differencing karena kita akan menemukan model arima secara otomatis.
Melihat nilai autocorrelation
Autocorrelation berguna untuk menganalisis hubungan antar lag atau bisa juga dikatakan untuk memperkuat kestasioneran data. jika bernilai tinggi, maka data memiliki autokorelasi yang berarti ada korelasi antara data ke n dan n+1, dan seterusnya.


Hasil yang diperoleh bahwa nilai autokorelasinya sangat tinggi sehingga memperkuat kesimpulan bahwa data ini tidak stasioner.
Dekomposisi melihat pola trend dan musiman
Tahapan ini, kita akan memisahkan antara komponen trend dan musiman. Apakah memang data ini hanya memiliki pola trend ataukah juga memiliki komponen musiman. Syntax yang diketikkan adalah:


Pada bagian “period=15” bisa anda gantikan dengan sau putaran musiman sebagai hipotesis. Misalnya data memiliki musiman triwulan, maka anda bisa menuliskan angka 3, dan sebagianya. Angka tersebut dari mana? Tentu anda sebagai data anlyst harus sedikit paham tentang karakteristik data yang sedang anda milliki. Hasil syntax tersebut sebagai berikut setelah di klik run (grafik secara otomatis tersimpan dengan nama “dekomposisi.png”.

Terlihat pada gambar yang dihasilkan bahwa data ini ternyata memiliki trend dan memiliki musiman. Data trend terlihat dengan adanya kenaikan data pada n 150 hingga 200. Sedangkan mmusiman ditunjukkan dengan adanya fluktuasi yang tetap dari 0 hingga 200. Jika melihat ini, memang sebaiknya kita menggunakan model Sarima. Tapi tetap akan saya gunakan sebagai contoh arima untuk perbandingan nanti menggunakan yang sama di Sarima. Pada baris terakhir yakni residu… adanya simpangan yang banyak pada n 150 ke 200 menandakan bahwa model tren dan musiman bergerak secara acak atau fluktuasinya / simpangannya besar yang berarti model trend dan musiman juga belum tepat merepresentasikan data.
Plotting data forecast
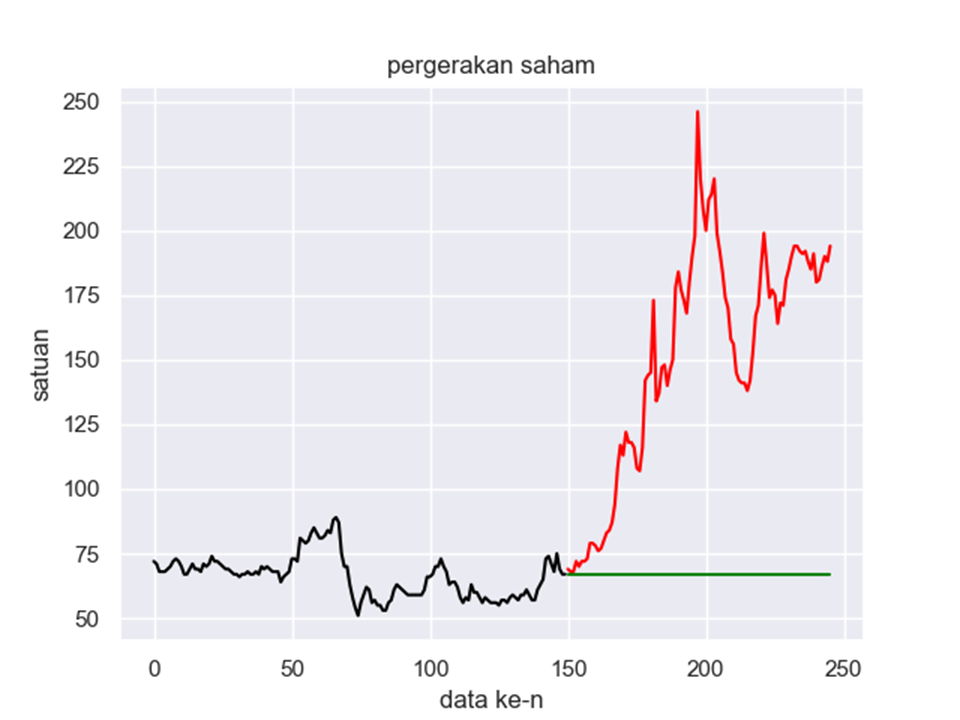
Pada tahapan ini kita ingin menetapkan n keberapa yang akan kita jadikan batas antara nilai real dan forecast. Pada latihan ini saya menetapkan nilai n=150 sebagai batas untuk wilayah real (sebelum) dan wilayah forecast (sesudah n=150).


Hasilnya sebagai berikut: wilayah grafik merah adalah wilayah forecast. Ini bukan hasil forecast, melainkan kita hanya memberi batas saja terlebih dahulu.


Menentukan model arima
Auto arima secara otomatis akan mencari model yang memiliki nilai AIC (Akaike Information Critera) terkecil. AIC merupakan suatu pengukuran untuk melihat kebaikmodelan dan data yang bersifat parsimony. Ini mirip dengan MSD namun AIC tidak hanya melihat error terkecil melainkan model mana yang paling efektif dan layak (misalnya ada dua model yang memiliki MSD yang sama, AIC bisa membedakan keduanya).
Syntax dan hasil auto arima adalah sebagai berikut:


Terlihat model ARIMA (0,1,0) dipilih karena memiliki AIC terkecil, yakni 717. Dibawahnya python langsung menghitung nilai forecastnya. Pertanyaannya, mengapa nilainya hanya satu angka? Hanya 67 u forecast 150 dan seterusnya. Pada model (0,1,0), model hanya didifferencing satu kali. Tidak ada pengolahan baik AR (auto regressive) ataupun MA (Moving average). Sehingga model hanya melihat data n-1 yang artinya seperti model naïve dan itu terus diberlakukan sampai n terakhir. Hal ini menguatkan bahwa model ini laykanya menggunakan model sarima yang akan saya bahas selanjutnya.
Membuat grafik forecast
Hasil forecast diatas, kemudian dimasukkan dalam grafik yang hasilnya adalah sebagai berikut: (hasil sudah tertera langsung dalam folder sebagai outputnya):
Semoga anda bisa paham jika ingin menggunakan analisis arima. Meskipun hasil akhir model tidak seperti yang diharapkan, justru ini akan mengundang pertanyaan untuk dibahas artikel selanjutnya. Model ini (arima) dapat digunakan dengan data trend yang kuat tanpa adanya musiman.
Demikian, Terima Kasih.











