
Mengolah Mudah Data Panel dengan Regression – Fixed Effect
Data panel sebenarnya tidak begitu berbeda dengan data yang lain. Jika anda melakukan regression pada data cross section atau time series, data panel merupakan gabungan keduanya. Cross section adalah sekelompok data dari beberapa objek penelitian di tahun yang sama; misalnya data produksi padi di setiap provinsi di tahun 2018. Sedangkan time series merupakan sekelompok data dari beberapa tahun/periode di satu objek penelitian, misalnya data produksi padi Provinsi Maluku dari tahun 1990 sampai dengan 2018. Data panel merupakan gabungan keduanya, yakni beberapa objek penelitian dengan beberapa periode atau tahun.
Keuntungan dari data panel ini jelaslah data yang diperoleh akan semakin banyak sehingga menghindari bias atau nilai error yang tinggi. Multikolinearitas juga bisa dihindari karena bauran data akan semakin banyak. Iya, intinya hasil data yang akan diperoleh akan semakin valid, meskipun tidak menjamin pasti valid. Mengapa? Karena sesuai kebutuhan. Regresi data panel hanya sebuah alat, sama dengan alat yang lainnya (regresi linear berganda), memiliki kelebihan dan kekurangan yang berbeda-beda. Dalam kasus tertentu, justru linear regression cukup dan valid untuk menjelaskan hubungan variabel independen terhadap variabel dependennya.
Kali ini saya akan mencoba berlatih untuk menggunakan data panel. Saya akan langsung praktek ketimbang teori. Karena sebelum saya menulis ini, saya menjumpai banyak literatur atau bahan referensi yang “bahasa”-nya sangat formal dan berbau makalah. Padahal bahasa blog seharusnya lebih familiar. Jadi, jika anda mencoba belajar memahami panel regression dengan cara santai terutama untuk mengatasi kebuntuan anda melakukan pengolahan panel regression, saya rasa artikel ini cukup tepat. Namun, jika anda mencari literatur untuk menambahkan bahan di metodelogi penelitian dan tinjauan pustaka, sebaiknya segera mencari artikel yang lain di mesin google 🙂
Saya menggunakan software Stata 12. Bahan latihan bisa di download disini:
Konversi data excel ke data panel
Pertama saya mencari data yang akan saya olah dengan panel regression, karena data panel merupakan gabungan cross section dan time series, maka harus ada kolom tambahan untuk menjelaskan pengelompokkan data tersebut.

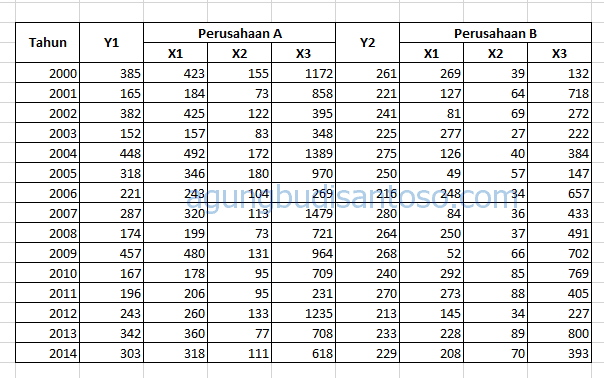
Tabel di atas menjelaskan bahwa terdapat 2 perusahaan yang masing masing memiliki variabel dependen (variabel Y) dan variabel independen (variabel X1, X2, dan X3). Tidak perlu kuatir karena data ini fiktif dan saya buat sendiri. Masing masing perusahaan memiliki data 15 tahun dan tentu jika saya proses regresi di setiap perusahaan, besar kemungkinan akan menemukan kendala karena data kurang dari 30 (minimal data regresi). Maka kedua perusahaan ini saya gabung dan sebagai konsekuensinya saya menggunakan regresi panel. Data tersebut saya ubah menjadi berikut:


Ada kolom tambahan yakni kolom perusahaan dengan kode 1 untuk perusahaan A dan kode 2 untuk perusahaan B. Data kemudian disusun memanjang kebawah. Data sudah siap untuk dipindahkan ke sheet data di Stata 12.
Intermezzo: “Mengapa sih saya menulisnya begitu detil? Karena terkadang saya mendapatkan pertanyaan yang sangat tidak saya duga dari pembaca untuk artikel-artikel sebelumnya; seperti bagaimana cara input data, bagaimana cara mengubah format, bagaimana cara membuka menu di software dll, pertanyaan yang dianggap remeh bagi sebagian orang”
Selanjutnya, mari kita buka software Stata 12, saya menggunakan software ini karena software yang biasa saya gunakan, minitab dan SPSS belum menyediakan fitur regresi panel.

Selanjutnya untuk memasukkan data yang akan diproses, kita klik data – data editor – data editor (edit)

Akan muncul data editor, mirip sekali sheet SPSS. Nanti kita perlu setting ulang variabel satu persatu.
Kemudian copi-kan data dari excell ke sheet stata tersebut. Datanya saja, tidak dengan judul atau nama variabelnya, karena nama variabel akan di setting satu persatu. Tampilan akan menjadi seperti ini:

Untuk mengubah nama label variabel kita klik kolom satu variabel, kemudian kita edit nama, label, type, format di pojok kiri bawah

Selanjutnya perlu diketahui untuk membuat label variabel yakni nilai 1 pada variabel company adalah perusahaan A, dan nilai 2 adalah perusahaan B. caranya anda klik data – data utilities – label utilities – manage value label
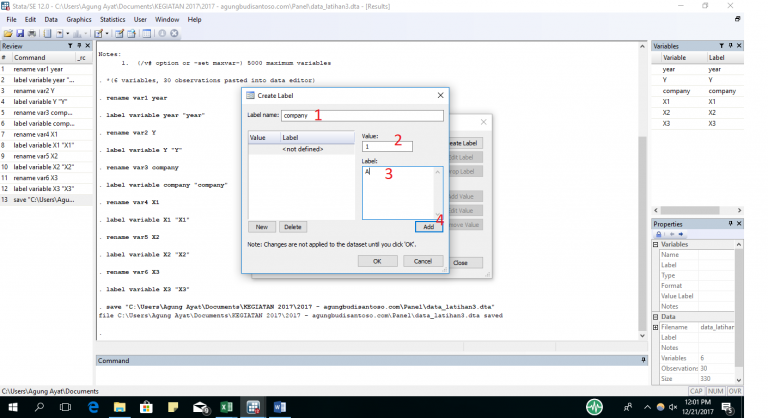
Kemudian klik create label


Isi label name sesuai kebutuhan. Dalam latihan ini saya tulis company, kemudian value saya isikan 1, label saya isi A.

kemudian klik add. Kemudian isikan lagi angka 2 dan B pada label, klik add. Sehingga tampilan seperti berikut:

Kemudian klik OK. Dan klik close
Kembali lagi ke data editor Stata. Kemudian klik data – variabel manager. Pada variabel company, pada value label, isikan company (data value label yang baru saja dibuat), kemudian klik manage. Kemudian klik apply dan tutup windows. Pada menu ini anda dapat mengatur lebih detil tipe variabel yang dibuat, sesuai dengan pengelompokan atau tipe data yang anada gunakan. Pada pilihan type ada pilihan byte, double, float, int, dan long.

Pada tahap ini, data siap untuk diregresi. Tutup data editor, kembali ke tampilan awal stata.
Jenis Panel regression
Sebelum saya melanjutkan praktek, saya sedikit menjelaskan beberapa pendekatan yang digunakan pada panel regression. Mayoritas peneliti membimbing kita untuk menggunakan 2 metode, yakni Fixed Effect, dan Random Effect. Sebenarnya ada satu pendekatan lagi, yakni common effect.
Common effect merupakan regresi yang umum beredar atau biasa disebut regresi sederhana atau regresi berganda. Pada regresi jenis ini, tidak memperhitungkan adanya perbedaan objek penelitian seperti perbedaan perusahaan, kampus, negara, provinsi, dan lain-lain. Selain itu, common effect juga tidak memperhitungkan adanya time series. Semua data dianggap satu tempat dan satu waktu yang kemudian diregresikan dan diketahui hasil – hasilnya. Untuk lebih jelasnya, saya sudah menjelaskan panjang lebar tentang regresi berganda beserta cara-cara memperoleh hasil yang maksimal.
Asumsi yang digunakan pada common effect tidak lagi relevan apabila ternyata ada perbedaan disetiap objek penelitian karena perilaku individu di tempat yang berbeda memungkinkan untuk memiliki nilai yang berbeda. Misalnya : terdapat penelitian tentang hubungan antara gaji dan pengeluaran (variabel independen = gaji, variabel dependen =pengeluaran). Kemudian peneliti tersebut mengambil 2 objek yang berbeda, yakni kelompok pegawai di perusahaan multinasional dan kelompok di perusahaan domestik. Kedua objek penelitian tersebut dikhawatirkan mempengaruhi nilai gaji karena berada dalam kondisi lingkungan yang berbeda. Maka dalam hal ini common effect tidak bisa digunakan.
Fixed effect digunakan untuk mengatasi permasalahan yang dijumpai pada common effect. Asumsi fixed effect ini adalah adanya kecenderungan objek penelitian (entitas) memiliki pengaruh terhadap nilai individu atau independen variabel. Fixed effect akan menghilangkan pengaruh tersebut sehingga diperoleh murni hubungan antara variabel dependen dengan independennya (tidak ada pengaruh object penelitian).
Asumsi kedua dari Fixed effect adalah bahwa object-object penelitian/entitas tersebut memiliki karakteristik tersendiri-sendiri sehingga kumpulan error masing-masing kelompok atau objek penelitian tersebut tidak dapat dikorelasikansatu sama lain. Biasanya peneliti menggunakan asumsi ini dengan cara menambahkan variabel dummy, karena pada variabel dummy dapat dengan mudah mengetahui secara parameter apakah masing-masing entitas tersebut berbeda.
Jika ternyata kelompok error dari setiap kelompok tersebut ternyata berkorelasi, maka Fixed effect tidak dapat digunakan, dan kita sebaiknya menggunakan Random effect. Random effect memiliki asumsi berkebalikan dari FE. Random effect memiliki pendekatan bahwa kelompok object penelitian diasumsikan memiliki pengaruh pada dependen variabel. Sehingga fokus pendekatan Random effect adalah pada bauran error-nya (seperti namanya, random effect.. 🙂
Bingung? Begini.. pada Fixed effect parameter entitas berbeda dan bauran errornya tidak berkorelasi. Jika keadaannya sebaliknya, entitas tidak berbeda maka besar kemungkinan bauran errornya akan memiliki hubungan atau korelasi dan selanjutnya besar kemungkinan ini akan mempengaruhi dependen variabel karena pada umunya sebaran error ini memiliki pola yang bisa diukur. Nah, pada kondisi seperti ini, fokus prosesnya pada errornya… sehingga yang digunakan adalah Random Effect.
Mengingat perbedaan dari kedua metode tersebut, fixed effect fokus pada perbedaan entitas dan Random Effect fokus pada errornya, maka kedua metode ini tidak bisa dikatakan satu lebih unggul dibandingkan lainnya. Saya pernah mendapat pertanyaan bagaimana caranya agar data bisa diolah dengan menggunakan RE, padahal saat dia menguji hipotesis, hasilnya sebaiknya fixed effect yang digunakan.
Secara model persamaan dan teori detilnya, anda akan menjumpai bahwa pada Fixed effect memiliki nilai intercept yang berubah namun slope yang sama. Karena sudah banyak literatur yang membahas ini saya tidak perlu membahasnya lagi.
“the crucial distinction between fixed and random effects is whether the unobserved individual effect embodies elements that are correlated with the regressors in the model, not whether these effects are stochastic or not” [Green, 2008, p.183]”
“If you have reason to believe that differences across entities have some influence on your dependent variable then you should use random effects”
Kedua kalimat ini sengaja saya kutip untuk menguatkan penjelasan saya diatas.
Pertanyaan umum: Lalu, metode mana yang harus digunakan? Pertanyaan bagus, tapi saya belum mau menjelaskan kearah sana. Mungkin saya bahas di artikel selanjutnya.
Mari kita lanjutkan prakteknya setelah teori sudah saya jelaskan … kembali ke stata dan data yang sudah kita input sebelumnya.
Proses Panel Regression
Langkah pertama adalah mendefinisikan variabel yang sudah diinput agar stata memahami bahwa data tersebut data panel yang terdiri dari 2 perusahaan dan beberapa tahun. Klik statistics – longitudinal/panel data – setup and utilities – declare data set to be panel data

Pada panel ID varibel kita isikan company atau diisi dari variable menjelaskan entitas yang kita gunakan. Pada latihan ini saya menggunakan variabel company yang menjelaskan ada data 2 perusahaan yang saya gunakan. Kemudian beri centang pada time series karena data yang kita gunakan mengandung data time series. Kemudian dibawahnya saya isikan variabel year yang menjelaskan data tersebut memiliki runtun waktu. Kemudian klik OK

Pada output akan terlihat sbb:


Selanjutnya klik statistics – longitudinal/panel data – linear models – linear regression

Masukkan variabel independen dan independen vaiabel, kemudian anda bisa memilih model type (affect which option are available) terdapat beberapa pilihan, kali ini saya coba pilih fixed-effect
Kemudian klik OK

Akan muncul hasil sebagai berikut:

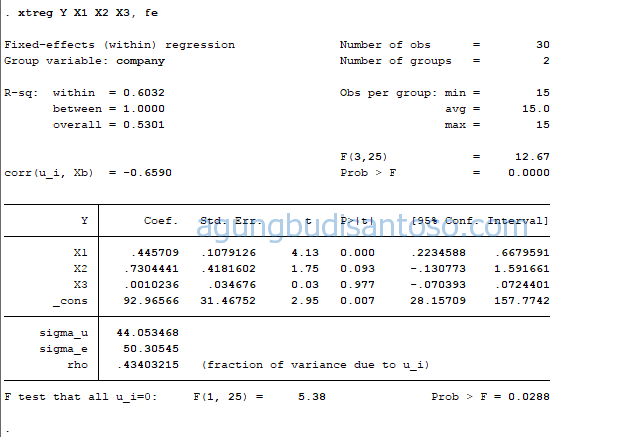
Interpretasi hasil
Interpretasi hasil pada data panel tidak berbeda dengan interpretasi regresi berganda. Disana terdapat R-Sq, Uji F, Uji T, P value. R squared menunjukkan berapa nilai dalam persentase data dalam model (independen variabel) dapat menjelaskan secara tepat variabel dependennya, sisanya dijelaskan dengan error atau variabel lain yang belum ada dalam model. Uji F menguji secara keseluruhan model, sedangkan uji T menguji satu persatu variabel dalam model. Untuk lebih jelasnya mari kita bahas satu persatu

No 1. Menjelaskan tentang Independen variabel (Y), dan dependen variabel (X1, X2, X3) dengan proses FE (fixed effect). Penjelasan di bawah regressi berdasarkan grup “company”
No 2. R Squared. Pada panel data terdapat 3 macam R-sq. Definisi R-Sq within merupakan R-Sq yang dari rata-rata deviasi regression yang diperoleh dari OLS transform data. Biar gampang: ini R-Sq umum yang biasa kita ketahui di regresi.
R-Sq between: Regresi FE ini awalnya menghitung nilai prediksi dengan menggunakan parameter Fixed effect dan rata-rata dari variabel independen. Kemudian nilai prediksi ini dihitung squared korelasinya dengan nilai rata-rata dependen variabel ( variabel Y)
R-Sq Overall: R-Sq diperoleh dari hasil kalkulasi squared correlation antara nilai prediksi dengan data nilai Y (bukan rata-ratanya). nilai prediksi diperoleh dari perhitungan fixed effect dengan nilai independen variabel (bukan rata-ratanya).
Mana yang lebih penting? Tentu ketiga-tiganya memberikan informasi penting. Namun jika fixed effect dicerminkan pada R-Sq overall.
Kemudian dibawahnya terdapat corr(u_i) merupakan penjelasan correlasi antara error dalam entitas/grup (u) dengan regressors dalam model (variabel independen). Seperti yang dijelaskan sebelumnya, sebaiknya nilainya kecil atau tidak berkorelasi untuk Fixed effect
No 3. Merupakan penjelasan tentang deskripsi observasi. Disana terdapat jumlah observasi, jumlah grup, kemudian paling bawah merupakan uji F. Model secara keseluruhan dikatakan baik apabila Prob>F dibawah 0.05 atau sesuai tingkat kepercayaan yang digunakan selama penelitian.
No 4. Merupakan nilai koefisien, uji T, P value secara individu. Variabel akan dikatakan memiliki pengaruh signifikan jika memiliki nilai P value kurang dari 0.05 atau sesuai dengan tingkat kepercayaan yang digunakan
No 5. Sigma_u dan sigma_e merupakan hal yang berbeda dibandingkan regresi. Seperti yang kita ketahui bahwa pada regresi panel terdapat komponen kelompok dan error, atau biasa dijabarkan dalam model dalam bentuk slope dan intersep. Pada sigma_u jika saya definisikan merupakan ke standar deviasi dari residu/error entitas atau kelompok dalam group. Sedangkan sigma_e merupakan standar deviasi dari error secara keseluruhan. Jadi error di data panel ada 2 ya… error keseluruhan, dan error entitas atau kelompok.
Untuk apa sih sigma ini? Nilai sigma ini akan memberi gambaran kepada kita tentang sebaran error baik dalam group maupun secara total. Contohnya: jika sebaran error secara total ternyata lebih tinggi, ada kemungkinan ada variabel yang belum masuk dalam model yang bisa mempengaruhi nilai Y. nilai rho menghubungkan kedua error tersebut. Jika nilai rho 0.297 artinya terdapat 29.7% varians yang disebabkan oleh perbedaan antara kedua kelompok error tersebut. Mana yang lebih bagus? Pasti mintanya variansnya yng lebih kecil karena berarti tidak begitu beragam sebaran errornya.


Wow… panjang ya…saya belum belajar ke arah dummy pada fixed effect, Random effect, Hipotesis yang menentukan kedua metode tersebut. Episode ini saya sudahi dulu. Sampai bertemu di episode selanjutnya. Jika ada penjelasan saya yang keliru, saya senang hati jika kita berdiskusi karena apa yang saya catat ini adalah hasil pembelajaran yang saya lalui.
Selamat Belajar!
Update 2 juni 2018
jangan lupa baca juga artikel yang berjudul: memilih fixed atau random dengan hausman test, yakni artikel yang menjelaskan tentang bagaimana cara hausman test memberikan rekomendasi kepada anda tentang regresi yang harus anda gunakan.







ijin bertanya pak apakah di regresi data panel dalam uji asumsi klasik.misalnya model yg terpilih dalah REM namun model tersebut masih terkena multikol dari beberapa variable independen. maka apakah variabel yg masih terkena multiko itu saja yang di trasnformasikan ke dalam log ataukah semua variabel independen yg tidak terkena multikol juga harus di transformasi ke log?
Variabel yang terkena multikolinearitas saja yang di log mbak…terima kasih
Halo ka, aku mau ijin nanya. Untuk penelitian skripsiku cross sectionku 6 perusahaan dari sampel dan untuk time seriesnya 4tahun dari 2017-2020. Untuk data panel ini kan gabungan antara cross section dan time series, berarti punyaku datanya 24. Apakah itu bisa dilakukan menggunakan data panel? Atau ada syarat minimal berapa data yg harus digunakan? Makasih ka mohon bantuannya
Jika melihat dari datanya, memang data seperti ini menggunakan regresi panel. Untuk minimal datanya, silahkan baca artikel saya tentang minimal data regresi. Terima kasih
Izin bertanya, apabila hasil regresi data panel dengan fixed effect model pada konstanta intersepnya tidak signifikan, apa pengaruhnya ya? Apakah intersep ini penting dalam model? Terima kasih
Intersep penting dalam pembahasan. Berisi nilai y jika kesemuanya nilai x bernilai 0. Terima kasih
Selamat malam Pak, izin bertanya. Untuk data panel saya menggunakan eviews, x4 saya menggunakan dummy pak. Saat akan menentukan model fem/rem apakah fungsinya y c X1 X2 X3 X4 X5 atau bagaimana pak?🙏
pertanyaannya agak detil ya.. sepertinya harus dijawab satu artikel. insha allah nanti dibahas.
Kak mau tanya data panel. variabel independen saya ada 1 yang menggunakan dummy (x5). Saya menggunakan eviews. Apakah ketika membuat model cem, fem atau rem menggunakan fungsi y c x1 x2 X3 X4 X5 X6 atau bagaimana kak?
Assalamu’alaikum pak..
Mohon izin bertanya mengenai data panel..
Apakah dalam pengolahan data panel di haruskan minimal n (jumlah data) 30?.
Atau bebas?? Rtinya dibawah 30 tidak masalah…
Terimakasih pak…
bebas.. dibawah 30 pun tidak ada masalah
Mohon maaf, saya Riski Dian..
kalau boleh tau literarurnya dari mana gih bapak?
mohon jawabannya bapak… untuk bukti literatur penelitian saya terhadap penguji saya
Ini bagian dari buku mas yang saya tulis. Silahkan cari di google dengan kata kunci “tutorial dan penholahan data regresi” .. terima kasih
mohon pak, izin bertanya lagi..
dalam buku gih pak?
kalau boleh tau di halan berapa gih?
mohon maaf pak,, izin bertanya..
dalam buku ada di halaman berapa gih?
sepertinya untuk topik minimal data ini blm saya masukkan ya.. klo begitu silahkan cari artikel ini..
Design of experiments and progressively sequenced regression are combined to achieve minimum data sample size
klo kesulitan downloadnya, hub admin wa untuk bantu. terima kasih
Selamat siang pak, izin bertanya jika ketika akan memilih model fixed effect di eviews keluar tulisan near singular matrix bagaimana solusinya ya pak? di penelitian saya ada 1 variabel dummny, jadinya saya tidak bisa melakukan uji chow. Mohon bantuan solusinya ya pak. terimakasih
near singular matrix berarti ada indikasi multikolinear. baru saja saya publish artikel tentang multikolinear. terima kasih
Assalamualaikum.
Pak izin bertanya, apakah dalam regresi data panel diharuskan 5 tahun penelitian jika kita sudah memiliki 5 variabel? (cross section data 12 kab/kota dan time series nya 2016-2020).. Apakah bisa hanya menggunakan 2 atau 3 tahun penelitian saja? Sy menggunakan eviews utk olah data nya.
Mohon penjelasan pak, beserta sumber buku nya agar saya bisa baca utk lebih jelasnya. Terima kasih.
wa alaikum salam, tentang data regresi memang semakin banyak data akan semakin baik. namun tidak ada kriteria khusus dalam menentukan sample. silahkan baca artikel saya yang berjudul minimal data regresi. terima kasih.
Mas mau nanya, kalau untuk mengetahui nilai intersep dr masing2 wilayah bagaimana ya? Model LSDV
Intersep itu koefisien dari masing masing variabel. Model apapun, pengertiannya sama..
Assalammualaikum pak Agung,
Saya menggunakan data panel dengan 3 variabel independen dan salah satunya menggunakan dummy, kemudian ada 1 variabel moderator menggunakan dummy juga, untuk regresi dengan variabel moderator dummy apakah bisa menggunakan eviews atau dengan MRA pada spss saja ? bagaimana cara menggunakan variabel dummy tersebut
terimakasih
wa alaikum salam, saya rasa cukup menggunakan eviews saja klo data panel. tentang bagaimana menggunakan dummy untuk moderator agak panjang jawabnya. tapi bisa dirun dua kali antara dengan dummy moderator dan tanpa dummy moderator tersebut untuk mengetahui apakah dummy moderator tersebut memperkuat atau justru memperlemah hubungan. cara teknis insha allah akan saya jelaskan di artikel terpisah. terima kasih
Selamat pagi pak, mau bertanya dengan regresi data panel menggunakan eviews, 1. apabila menggunakan tambahan variabel dummy apakah tetap dilakukan uji chow dan uji hausman? 2. Jika dilakukan 2 uji tersebut muncul near singular matrix, apa yang harus dilakukan?
Near singular matrix biasanya karena multikolinear.
Pak, untuk regresi data panel yang menggunakan dummy apakah pilihanya selalu pendekatan fixed efek? apakah tidak perlu dilakukan uji chow dan hausman lagi?
sebaiknya gunakan uji chow dan hausman. ini untuk lebih meyakinkan saja. terima kasih
Assalamualaikum, Pak penelitian saya 5 perusahaan 8 tahun, 3 x & 1 y salah satu x saya variabel dummy. Jika hasil pilih model ternyata fixed, apakah hasil regresinya akan bias atau menjeadi tidak baik? maksudnya jadi double si dummy nya.
Penentuan fixed atau random itu dari sebaran error. Meskipun memang akaj dipengaruhi oleh skala data independen, saya rasa tidak masalah jika dummynya masih wajar.
assalamualaikum wr.wb pak saya 3 x 1 y , salah satu variabel independennya ada dummy. data saya data penel. akan bermasalah tidak ya kalo nanti pas memilih model malah dapet fixed effect? maksunya malah jadi double fixed?
Sepertinya tidak ada masalah
Syarat data time series minimal brp tahun pak. Jika ada 3 wilayah observasi dan ada 3-4 variabel dependentnya apakah memenuhi syarat untuk d regres?
tidak ada syarat minimal berapa tahun karena ini regresi bukan analisis time series. terima kasih
mas mau tanya,untuk proyeksi data pajak daerah tahun 2011-2019
apakah menggunakan regresi time series atau panel?
terima kasih
lebih tepatnya time series. terima kasih
kalau data times series apakah harus melalui proses stasionerisasi data?
data yang ada berupa data tren,tidak terdapat data bersifat siklus dan musim?
semoga berkenan menjelaskan step by step mengolah data trend seperti kasus saya di atas.terima kasih atas pencerahannya
sebelumnya saya perlu menegaskan yang dimaksud pertanyaan ini adalah proyeksi ya? saya sedikit bingung karena pertanyaannya tidak sesuai artikel. oke, jika memang yang dimaksud adalah proyeksi, maka sebaiknya membaca artikel atau kumpulan artikel saya tentang time series. diantaranya ada arima yang membahas tentang tren. juga ada video tutorialnya di youtub. jangan lupa subscribe. terima kasih
Mas, cara mendapatkan data cross section itu dari mana ya?? kalau time series kan dari BPS biasanya.
contoh : data laju pertumbuahn indonesia 2016-2020 (time series nya kan sudah ada)
kalau cross sectionya itu dr mana ya mas ya ?
terima kasih
Dengan sumber yang sama, jika ada data pertumbuhan provinsi, maka akan diperoleh data cross section karna datanya antar provinsi. Jika mau tingkat mancanegara, tentu cari sumber internasional. Sebagai contoh untuk data produksi pertanian bisa mengacu sumber FAO. Terima kasih
Mlm pak, untuk pengujian yang menggunakan variabel dependen bersifat dummy, namun data yang diolah adalah data panel, apakah cara pengujiannya di eviews tetap sama dengan yg dependennya bersifat interval? atau jika dependennya dummy diwajibkan menggunakan analisis regresi logistik di SPSS?
Dan untuk penghapusan outlier di SPSS, apa lebih baik menghapus dengan cara Z Score atau SDR? Makasih banyak pak.
pagi mbk.. saya tidak mewajibkan ya mbk.. karna jika dilihat prinsipnya, jika variabel dependennya dummy maka regresi logistik yang digunakan. Sedangkan regresi panel ada di variabel independen.
berbicara variabel dependen yang berbentuk dummy adalah berbicara peluang. jadi koefisien di model akan memperhitungakan peluang responden untuk bisa berada di kelompok 1 atau 0. lalu jika ini dipaksakan ke regresi panel yang notabene masih menyerupai regresi berganda, bagaimana mbk nanti menginterpretasikannya?
kecuali model yang keluar nantinya di regresi panel dikonversikan ke rumus odds. tapi terus terang belum menjumpai ini.. terima kasih
Pak mau tanya kalo panel data dengan LSDV itu proses regressinya apakah berbeda?
Justru data lsdv biasanya menggunakan dummy dan menggunakan fixed effect. Terima kasih
Pak, apakah setelah memilih model (fixed effect), Masih perlu dilakukan uji asumsi klasik? Bila jawaban iya / tidak, boleh mencantumkan alasan dan referensi (judul buku) yang digunakan?
Maaf mbk, sampai skr saya blm menjumpai buku yang khusus tentang regresi panel.
Tapi, jika dilihat dari sifat dan karakteristik regresi linear dan panel, keduanya memang sama. Yang membedakan hanyalah panel mengevaluasi error yang terbentuk akibat adanya duplikasi dari objek penelitian.
Sedangkan sifat OLs dan linearitas dari reg panel masih mengikuti regresi linear. Contoh: apabila terjadi kasus multikol pada reg panel, tentu dampaknya sama dengan yang terjadi di reg linear. Itu karna sifat keduanya masih menggunakan pola yang sama (ols dan linearitas).
Terima kasih
Jadi saya rasa..buku apapun tentang regresi bisa digunakan untuk menambahkan uji asumsi klasik pada reg panel
Maaf Pak mau tanya, kalo judulnya pengaruh kredit bermasalah terhadap laba, untuk datanya sendiri diambil dari Bursa efek indonesia sampelnya 3 bank swasta kurun waktu 5 thn. Yg ingin saya tanyakan itu diolah data apa? Apakah termasuk data panel? Terimakasih
iya mbk nia, jika melihat sumber data yang diambil, data tersebut termasuk data panel. terima kasih
maaf bole saya tanya app stata itu di download? trus kalo di spss apakah memang tidak bisa melakukan uji dengan data panel?
Kami tidak berafiliasi dengan software statistik, jadi untuk mendapatkan software silahkan mencarinya di situs lain atau situs resminya. Setau penulis regresi panel blm bisa dioperasikan di spss. Terima kasih