Memahami R-square secara konsep pada regressio diperlukan untuk membuat sebuah penelitian yang dapat dengan mudah menemukan solusi dan penyelesaiannya. Mayoritas mereka yang bertanya tentang mengapa hasil r-square yang kecil karena belum sepenuhnya mengerti konsep dari R-square.
R-square seolah merupakan hasil wajib yang harus diperoleh oleh mahasiswa atau peneliti yang menggunakan regresi sebagai alat penelitiannya. Hampir 50% dari mahasiswa yang meminta solusi atau bimbingan statistik meminta masukan tentang r-square yang kecil.
Mari kita bicara secara teori, R-square merupakan nilai persentase jumlah data dari variabel independen yang secara bersama-sama mempengaruhi varaiabel dependen, sedangkan nilai 1 – (r-square) merupakan nilai yang tidak bisa dijelaskan dalam model tersebut, atau biasa kita sebut dengan nilai error.
Lalu, bagaimana jika ternyata kita mendapati error yang lebih tinggi dibandingkan r-squarenya? Berdasarkan teori tersebut berarti model yang dihasilkan dari regresi tidak baik dan kemungkinan besar terjadi kesalahan definisi dan hipotesis awal. Dengan kata lain, hipotesis penulis tentang adanya hubungan antara variabel independen ke variabel dependen secara simultan tidak terbukti.
Guna menghindari kejadian yang tidak diharapkan, berikut tips yang dapat dilakukan sebelum melakukan sebuah penelitian:
Identifikasi variabel
Pikirkan secara matang, dugaan adanya hubungan antara variabel independen ke variabel dependen memanglah kuat. Bila diperlukan, untuk lebih meyakinkan, cari literatur atau baca penelitian penelitian terdahulu untuk menerangkan hubungan tersebut. Mencari literatur dan membaca penelitian terdahulu tidak hanya mencari apakah hubungan variabel independen berpengaruh kuat terhadap variabel dependen, namun juga melihat apakah variabel yang akan anda gunakan sudah pernah dibahas oleh penelitian sebelumnya dan anda bisa melihat hasilnya, yang kemudian anda bisa analisis dengan kondisi yang akan anda temui nantinya di lapangan.
Apabila memang ditemukan adanya variabel yang meyakinkan berpengaruh terhadap variabel Y, gunakan variabel yang berpengaruh kuat tersebut minimal satu variabel. Lebih bagus jika ada hukum atau teori kuat yang mendukungnya atau sebuah hubungan yang tidak bisa dibantah lagi. Misalnya, apabila anda menambahkan variabel luas lahan terhadap produksi padi, tentunya akan mendapat hasil yang signifikan karena luas lahan termasuk kedalam faktor produksi. Hasil tentu akan berbeda jika anda mengganti luas lahan dengan variabel kerusakan lahan hutan terhadap produksi padi.
Hal yang saya sampaikan ini tidak bertujuan untuk menyamakan semua penelitian sehingga hanya berorientasi terhadap nilai R-square nya saja. Akan tetapi jika peneliti memang yakin dengan fenomena variabel yang tidak umum tersebut dapat mempengaruhi variabel dependen, maka variabel tersebut bisa digunakan. Fenomena yang tidak umum misalnya bisa diindentifikasi awal dengan menggunakan korelasi antar kedua variabel tersebut. Karena regresi dan korelasi merupakan dua alat analisis yang sama tapi tidak serupa. Korelasi menjelaskan hubungan kuat/lemah/sedang antara dua variabel, namun tidak bisa digunakan apakah salah satu variabel tersebut mempengaruhi variabel lainnya. Sedangkan regresi yang merupakan alat analisis yang berada di satu tingkat lebih tinggi dibandingkan korelasi, mampu menjelaskan hubungan kuat/lemah/sedang dan dapat menjelaskan bahwa variabel independen mampu mempengaruhi nilai variabel dependen.
Artinya, jika hasil regresinya baik dan kuat, otomatis nilai korelasinya juga kuat. Namun tidak berlaku sebaliknya, jika nilai korelasinya kuat belum tentu hasil regresinya baik dan kuat. Paham???
Gunakan logika saat identifikasi hipotesis
Setelah anda menetapkan varaibel independennya, pikirkan dengan matang apakah variabel yang digunakan memang secara nalar dan logika memang dapat dijelaskan hubungannya. Bagaimana pun regresi merupakan alat analisis yang tidak bisa mengkonfirmasi hasil nya sendiri. Dalam regresi ada yang dikenal sebagai regresi palsu. Sebagai gambarannya akan saya berikan sebuah ilustrasi:
Ada data jumlah ibu hamil dan tinggi tanaman bawang merah. Keduanya diregresikan dan ternyata menghasilkan regresi yang baik. Tentu secara nalar tidak pernah dapat dibuktikan bagaimana tinggi tanaman bawang merah mempengaruhi jumlah ibu hamil di suatu wilayah? Inilah ilustrasi dari regresi palsu.
Fenomena regresi palsu ini biasanya karena penulis tidak memiliki hipotesis kuat dan hanya terpaku pada hasil regresi. Padahal, sekali lagi saya katakan regresi adalah sebuah alat. Minitab atau SPSS tidak akan pernah mengenal apakah data yang dimasukkan kepadanya adalah data yang masuk akal atau tidak. Mereka hanya mengerjakan perintah sintax untuk menentukan hubungan antara kedua variabel yang anda masukan.
Tetapkan jumlah responden melebihi batas untuk regressio
Kepada siapapun yang meminta bimbingan ststistik kepada saya,saya selalu menyarankan untuk mencari responden melebihi yang sudah ditetapkan olehnya ataupun oleh dosennya. Tujuannya adalah agar penulis bisa melakukan eliminasi responden. Jika minimal regresi sudah dapat menghasilkan analisanya dalam jumlah minimal responden 30, maka sebaiknya andamendapatkan 60 samai 100 responden jika memungkinkan. Rasa lelah yang diperoleh saat berjuang memperoleh responden akan trebayar saat anda meregresikan variabel tersebut dan dapat dengan leluasa memilih responden untuk mendapatkan r-square yang lebih baik.
Perlu saya tekankan disini perbedaan eliminasi responden dengan sampling dan rekayasa data. Eliminasi responden akan salah apabila anda menggunakan responden diluar daerah sample yang anda tentukan. Maka tetapkan berpedoman terhadap daerah sampling yang sudah ditetapkan, juga termasuk teknik samplingnya. Eliminasi responden akan bisa dilakukan jika anda menggunakan random sampling dalam menentukan responden. Adapun jika anda menggunakan teknik sampling dengan responden yang sudah ditetapkan, tentu ini tidak berguna karena anda tidak diperkenanan memiliki pilihan responden lain.
Kemudian perlu dijelaskan tentang eliminasi responden dengan rekayasa data. Kedua hal ini sangat sangat sangat berbeda. Yang dimaksud eliminasi responden adalah kita mengganti responden satu dengan responden lainnya. Jika kita menemukan variabel x di no data ke-n memiliki masalah, maka anda dapat menghapus responden tersebut. Artinya baik nilai Y, X1, X2, dst dari responden tersebut dihapus.
Jika anda hanya mengganti nilai x yang bermasalah tadi dengan nilai x dari responden lain (hanya mengganti 1 variabel saja, tidak menghapus semua), anda masuk kedalam kategori manipulasi data atau rekayasa data dan ini SANGAT tidak diperkenankan. Jika memang data ini disayangkan untuk dibuang, maka sebaiknya anda datang ke responden yang dimaksud untuk mengkonfirmasi jawabanya apakah akan ada perubahan pada jawabnnya.
Dan maniulasi data atau rekayasa data ini sangat mudah untuk dibuktikan, dan saya rasa dosen anda juga mengetahui cara membuktikannya. Tentu saya tidak akan membahasnya disini.. 🙂
Oke, berdasarkan judul dari artikel ini tentang memahami r-square secara konsep. Saya akan memberikan sebuah contoh bagaimana kita bisa meningkatkan nilai r-squre dengan cara tehnik eliminasi dan konsep dari r-square.
Data untuk latihan memahamikonsep R-square silahkan di download disini:
Pada file excell tersebut terdapat 4 sheet, data awal, seleksi 1, seleksi 2, dan seleksi 3 (final). Data awal merupakan keseluruhan data yang akan diolah dengan jumlah 3 variabel independen. Mari kita running regresi di minitab atau spss. Saya mendapatkan hasil yang tidak diharapkan, sebagai berikut:

R-square yang diperolah hanya 6 persen saja. Artinya sekitar 94% bauran datanya adalah error. Jika anda menjumpai hal begini, jangan kecewa dan stress dulu ya… mari kita perhatikan lagi hasil regresinya. Dari nilai individual, P value untu nilai X1 dan X2 adalah signifian karena dibawah 0,05. Ini adalah pertanda baik. Kemudian nilai VIF juga normal, tidak ada identifikasi multikol.
Kemudian kita lihat koefisien nilai X1 dan X2 ternyata bernilai positif. Artinya hubungan X1 dengan Y adalah hubungan searah. Jika X1 tinggi maka Y akan rendah, sebaliknya jika X1 rendah, maka Y juga ikut turun. Hal ini berlaku juga untuk variabel X2.
Nah, tiba juga di titik point dimana kita akan mengimplementasikan bagaimana mengeliminasi responden dengan konsep R-square. Pada kali ini, saya mengasumsikan bahwa X1 akan benar-benar berhubungan kuat terhadap Y. Kemudian kita ketahui bahwa R square nilainya 6% selebihnya error. X1 berhubungan searah dengan Y.
Maka, saya akan mengeliminasi data responden yang memiliki nilai X1 yang berbalik arah dengan variabel Y. Artinya jika nilai X1 sama dengan 0 tapi memiliki nilai Y diatas 1.5 maka masuk dalam ketegori eliminasi. Begitupun jika ada nilai X1 sama dengan 1 namun memiliki nilai Y dibawah 1.5 atau dibawah 1.4, juga masuk kategori eliminasi.
Responden yang saya eliminasi, masih berada di sheet data awal, kemudian saya arsir kuning di variabel x1. Responden yang saya arsir kuning tersebut kemudian saya eliminasi (delete row di excel) dan hasilnya ada di sheet seleksi 1. Kemudian mari kita run regresi kembali dan hasilnya adalah:

R square nya sudah naik ke 39% dan r-squarednya sudah menjadi 36%. Masih merasa kurang? Saya pun melakukan eliminasi lagi dengan cara yang sama seperti sebelumnya, kemudian hasilnya ada di sheet seleksi 2. Hasil regresinya adalah:
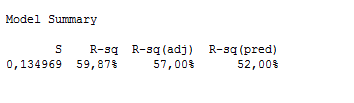
Hasilnya adalah 57%. Saya rasa r square akan dikatakan cukup bila diatas 60 persen, maka saya pun lakukan seleksi lagi (untuk ketiga kalinya) dan hasilnya saya ada di sheet seleksi 3(final). Kemudian saya regresikan dan hasilnya adalah sebagai berikut:

R-square yang diperoleh sebesar 64.73 persen dengan jumlah responden awal 105 responden menjadi 57 responden. Saya berhenti sampai disini karena nilai ini sudah tidakbisa dipaksa kembali. Jika terlalu over mengeliminasi nantinya akan timbul complete separation. Apa itu? Suatu saat akan saya jelaskan jika ada waktu.
Artikel ini saya tutup dengan pernyataan bahwa kita sebagai peneliti diperkenankan mengeliminasi responden selagi masih dalam lingkup samplingnya. Kejujuran pelaku peneliti sangat diharapkan karena hasilnya akan dipertanggungjawabkan.
sebelum artikel ini, saya juga pernah menuliskan cara lain untuk mengeliminasi data responden agar mendapat R square yang baik. dan juga cara mengeliminasi variabel pada regresi
Selamat Belajar …
Selamat siang, kak.
Izin bertanya, penelitian saya data sekunder dan time series, menggunakan PLS. R-square 0,997.
Namun dari 6 variabel independen, hanya 1 independen yang berpengaruh terhadap dependen. Apakah ini normal?
halo.. jika dilihat ciri-cirinya, sepertinya model terkena “over Fit”. apa itu? buat gambaran, baca artikel ini untuk kasus regresi logistik:
https://agungbudisantoso.com/mengenal-dan-mengatasi-complete-separation-pada-regresi-logistik/
untuk regresi berganda sama juga..hanya bedanya dia bukan pengelompokkan, melainkan garisnya tepat linear.
Selamat siang Kak. Mohon izin bertanya, apabila nilai R, R Square dan Adj R Square semuanya adalah 1,000 apakah hal tsb tidak bermasalah? lalu bagaimana cara menurunkan nilai agar ketiga nilai tsb tidak sama? karena dosen bilang untuk nilai ketiga nya tidak boleh sama. Terimakasih
selamat malam. bukan tidak boleh kak.. tapi model anda mengalami over FIT. kemungkinan model tersebut nilai Y nya didapat dari rumus nilai X secara langsung. terima kasih
Boleh boleh bantu saya meningkatkan nilai adjusted r di Uji koefiens determinasi bisa gk?
Bukannya dengan mengeliminasi responden hanya demi menambah nilai r square jumlah sampel akan berkurang dan dengan demikian berpengaruh pada keberlakukan hasil penelitian tersebut pada seluruh populasi?
pertama, jumlah sample yang dieliminasi tidak perlu banyak banyak. cukup beberapa error tertinggi. kedua, itulah pentingnya melebihkan sample ketika penelitian untuk mengganti sample yang tereliminasi. terima kasih
izin bertanya kak, apakah metode eliminasi ini bisa digunakan untuk selain data jenis responden, karena data penelitian saya mengenai pengaruh hambatan terhadap kecepatan? Bagaimana ya kak baiknya apakah cara ini bisa diguakan karena nilai r2 saya sangat kecil, mohon pencerahannya kak, terimakasih
bicara tentang hambatan dan kecepatan saya jadi ingat pelajaran fisika.. yang dimaksud data responden disini adalah data sample. jadi sumbernya bisa responden bisa juga data sekunder, data yang mbak maksud itu juga bisa. terima kasih.
Izin bertanya kak. Jadi saya sedang melakukan penelitian menggunakan variabel independen yang cukup banyak yang terdiri dari 6 variabel dummy dan sisanya data rasio. Variabel dependennya berupa data indeks dengan jumlah sampel 390 an. Dasar penentuan variabel ini sudah mengacu pada jurnal, satuannya juga sama. Metode pengujian yang saya gunakan pun sama dengan jurnal. Tetapi mengapa nilai R square nya sangat kecil, hanya sekitar 6%. Dari hasil multikolineritas juga sudah lolos.
Saya sudah mencoba memecah menjadi beberapa model, sudah mencoba menambah variabel lain juga dan hasilnya masih sama. Mohon arahannya kak. Terimakasih sebelumnya
multikolinier terjadi karena data yang mbak peroleh masih memiliki hubungan rumus. apalagi mengambil data indeks.. coba periksa satu persatu dulu variabel independen terhadap variabel dependennya. running regresi sederhana satu persatu kemudian mbk akan menemukan gambaran kira kira variabel mana yang akan dimasukkan. atau gunakan forward dan bakward metode di spss.
terkait dengan r square yang sangat kecil, berarti memang variabel variabel tersebut belum signifikan mempengaruhi variabel dependen. jawaban nya sangat normatif ya… tapi prediksi saya, karena data ini indeks pasti datanya tidak menyebar. coba buat histogram dari data tersebut.. nanti akan diketahui karakteristik datanya. terima kasih
Terimakasih atas jawabannya kak. Mohon izin untuk menyambung pertanyaan lagi ya kak
Jadi saya sudah mencoba menggunakan metode backward dan stepwise, namun model yang ditemukan itu memang tidak bisa semua variabel masuk, hanya beberapa variabel independen saja dan ini belum mewakili penelitian saya. Disini juga R squarenya masih tetap rendah kak, hanya meningkat sedikit menjadi 10%.
Setelah saya baca2 referensi, saya mencoba mendeteksi outlier. Dan hasilnya memang benar data saya mengandung outlier. Nah untuk kasus data outlier ini cara mengatasinya bagaimana ya kak? Apakah tetap bisa menggunakan model regresi linier berganda dengan OLS? Terimakasih
Klo memang outlier, masih bisa dengan regresi berganda. Eliminasi dulu error tertinggi. Silahkan berkunjung di channel youtube saya dan cari video meningkatkan r squared. Terima kasih
Selamat siang ka. Saya izin bertanya, penelitian saya menggunakan data panel serta 5 variabel. 1 variabel y dan 4 variabel x. Variabel y saya menggunakan dummy. Saya memakai eviews utk olah datanya kak. Setelah itu nilai R-Square nya 1.000 apakah itu tidak apa2 ka?
Silahkan baca artikel ini:
https://agungbudisantoso.com/mengenal-dan-mengatasi-complete-separation-pada-regresi-logistik/
Penelitian saya data sekunder dan time series. Memiliki R-Squared diatas 75% dengan variabel dependen 1 dan variabel independen 5. Apakah R-Squared tersebut perlu di perbaiki? Saya bimbingan dengan dosen saya bahwa variabel yang jumlahnya 5 dengan R2 diatas 75% itu terlalu tinggi. Lalu bagaimana cara menurunkan nilai R2? Terima kasih mohon bantuannya.
R square tidak berhubungan dengan jumlah variabel independen meskipun ada yang mengatakan semakin banyak variabel independen semakin baik r squarednya. jawaban lebih detil silahkan melihat video TJBudi#02. terima kasih
penelitian saya menggunakan data cross section dengan jumlah responden 100 orang dan nilai R squarenya 38,1%. apakah nilai RSquare sudah bagus atau tidak?
R square nya kecil sekali. Sangat perlu diperbaiki. terima kasih
penelitian saya menggunakan data cross section dengan jumlah responden 100 orang dan nilai R squarenya 38,1%. apakah nilai RSquare sudah bagus atau tidak?
Belum bagus. Ini kecil sekali. Terima kasih.
mau tanya dong, ada ga cara lain meningkatkan Rsq selain mengeliminasi responden, kalo dg transformasi data, penambahan atw mengganti variabel kira2 memungkinkan tdk ya Rsq nya bisa meningkat?
Gunakan regresi non linear. Silahkan cari artikelnya diblog ini
gan mau tanya dong, R square minimal untuk sebuah menelitian itu di titik berapa ya? boleh di referensi dong gan buku yang dapat saya cari untuk penjelasan lebih detailnya.
Kategori baik itu diatas atau sama dengan 0.75. Dibawah 0.6 itu sudah kurang.
Untuk buku ga perlu jauh jauh gan. Lihat di blog ini juga jual buku soal regresi.. terima kasih
Apakah ada penjelasan nya di youtube , biar lebih gampang mempraktekan nya ?
Youtube belum ada, tetapi buku sudah ada. Silahkan dipesan dan bisa puas memahaminya. Terima kasih