Jika anda sudah paham dengan judul diatas, saya berasumsi bahwa anda sudah mengerti tentang tehnik dasar regresi berganda. Karena pada artikel ini saya akan membahas ketiga perbedaan analisis tersebut, sehingga point dasar pada regresi sudah dianggap paham sebelumnya. Akan lebih senang jika anda sudah mengenal ketiganya, karena catatan ini merupakan resume dari hasil pembelajaran, sehingga akan lebih baik jika ada yang bisa menambahkan.
Ketiga analisis tersebut, regresi, path analysis, dan SEM structural equation modeling merupakan alat analisis yang menceritakan korelasi antar dua atau lebih peubah. Namun terdapat perbedaan mendasar dari pemakaian dan ciri khas penggunaan masing-masing. Diharapkan setelah anda membaca artikel ini mampu memilih analisis yang akan digunakan dan menyiapkan data sesuai dengan analisis tersebut. Maksud kata “menyiapkan data” disini adalah mensinkronkan skala pengukuran data terhadap persyaratan minimal yang diperlukan sehingga tidak terjadi pengulangan survey ke lapangan.
Regresi
Regresi terdapat beberapa jenis, regresi sederhana, berganda,logistik, dan panel. Kesemua jenis regresi itu menceritakan tentang hubungan langsung antara independen variabel terhadap dependennya. Jenis hubungannya “langsung dan searah”. Langsung berarti masing masing variabel independen berkorelasi dengan dependen tanpa melihat adanya hubungan antar variabel independen. Bahkan multikolinear tidak diperkenankan dalam regresi. Jika ada multikoliniear, atau korelasi antar variabel independen justru akan menggangu kebaikmodelan sebuah model regresi.
Maksud dari kata searah bahwa tidak akan ditemui dalam regresi hubungan timbal balik. Jika X mempengaruhi Y maka artinya hubungannya hanya mengarah dari X ke Y. Padahal, dalam kehidupan sehari-hari terutama pada penelitian sosial, sulit ditemui variabel yang berdiri sendiri dan hanya memiliki hubungan searah. Misalnya jumlah tenaga kerja dan pupuk mempengaruhi produksi. Besar kemungkinan tenaga kerja juga mempengaruhi ketersediaan pupuk. Artinya peran tenaga kerja selain memiliki hubungan langsung terhadap produksi juga sebenarnya memiliki hubungan tidak langsung melalui variabel pupuk. Selain itu, produksi yang tinggi jika dipikirkan juga mempengaruhi tenaga kerja lho? Bayangkan jika pemerintah memiliki rencana LTT tanpa ada petani di daerah?
Jika demikian, mengapa kita gunakan regresi? Artinya regresi tidak baik untuk sebuah penelitian? Penelitian terbagi dari berbagai jenis, salah satunya adalah penelitian dasar. Dengan berasumsikan cateris paribus, kita bisa melihat karakteristik hubungan antar variabel melalui regresi. Sama halnya dengan penelitian pilot yang mengkondisikan lingkungan ideal dan mengamati perilaku dari objek penelitiannya, sifat dari regresi mirip seperti itu dalam lingkup sosial. Maka jika anda ingin megetahui pengaruh dasar suatu variabel terhadap variabel lain, maka anda sebaiknya menggunakan regresi, bukan dengan path ataupun SEM structural equation modeling, karena path dan SEM structural equation modeling sifatnya adalah confirmatory analysis. Terlebih lagi jika anda akan menggunakan suatu persamaan untuk memprediksi nilai Y, jelas regresi akan lebih baik dibandingkan yang lainnya.
Oke.. tidak perlu berlama lama teori, kita praktek. Namun dalam sub judul regresi ini saya tidak praktek langsung karena sudah banyak saya menulis artikel tentang regresi termasuk tips mendapatkan model yang baik. Silahkan anda melihat kumpulan artikel tentang regresi di blog ini, atau membaca buku regresi.
Kumpulan artikel tentang regresi
Path analysis
Path analysis merupakan analisis yang digunakan untuk kajian hubungan yang berbentuk sistem. Kata hubungan merujuk kepada nilai korelasi. Path analysis menjelaskan hubungan langsung dan tidak langsung antar peubah baik itu independen maupun dependen variabel. Dengan begitu, persyaratan multikolinear tidak berlaku di path analysis, karena justru multikolinear itulah yang akan dibahas dalam Path untuk menunjukkan hubungan tidak langsung. Hubungan langsung dan hubungan tidak langsung ini nantinya akan dijumlahkan untuk mengetahui total hubungan variabel independen ke variabel dependennya.
Path analysis bersifat confirmatory, bukan explanatory. Jadi, variabel variabel yang digunakan dalam path harus didasari oleh teori atau setidaknya penelitian terdahulu. Berbeda halnya dengan regresi yang mengasumsikan cateris paribus, bisa digunakan untuk explanatori yang hasilnya dikonfirmasi dengan path analysis ini. Jika anda hanya ingin mengkonfirmasi teori bahwa ada hubungan X dan Y dan tidak menggunakan rumus persamaan untuk memprediksi nilai Y, maka path bisa menjadi pertimbangan.
Asumsi dasar yang digunakan dalam Path adalah model linear dan semua peubah diukur dalam skala minimal interval. Jadi tidak ada ceritanya variabel dummy dibuat dalam path ini, jika toh sudah terlanjur ada maka harus dilakukan konversi terlebih dahulu.
Asumsi kedua bahwa spesifikasi model adalah benar sehingga semua model kausal ditentukan dari model sebenarnya. Ini mengacu kepada sifat dari path analysis yang merupakan konfirmasi dari sebuah model.
Error antara variabel independen tidak berkorelasi. Juga antara sesama error tidak berkorelasi. Hal ini menunjukkan bahwa path analysis mengasumsikan bahwa error benar benar menyebar (tidak berpola) yang artinya bahwa model sudah bersifat fix linear dan sebab akibat (masih ingat pola error yang berpola di regresi panel?)
Dalam satu hubungan tidak diperbolehkan satu peubah menjadi peubah penyebab sekaligus peubah akibat. Jadi pembagiannya tetap jelas antara variabel penyebab dan variabel akibat.
Perhatikan gambar berikut:

Jadi antara X dan Z ada dua hubungan, yakni hubungan langsung yang mengarah ke Z, dan hubungan tidak langsung melalui V maupun melalui Y.
Variabel V dan Y inilah yang dinamakan dengan variabel mediator. Variabel ini yang bisa memperkuat hubungan X dan Y bisa juga sebaliknya, justru melemahkan. Nanti bisa dilihat dari tanda negatif atau positif nilai korelasinya.
Ada dua jenis anak panah dalam gambar nantinya, panah satu arah yang menunjukkan hubungan kausalitas (sebab dan akibat) dan panah dengan dua arah yang menunjukkan hubungan korelasional.
Lalu bagaimana cara menghitung total hubungannya?
Perhatikan gambar berikut:

Hubungan X ke Z
Pengaruh Langsung: X->Z = -0.2
Pengaruh Tak langsung:
X-V-Z = -0.1 x 0.4 = -0.04
X-Y-Z = 0.5 x -0.6 = -0.30
X-Y-V-Z = 0.5 x -0.5 x 0.4 = -0.10
Total pengaruh X ke Z = -0.2-0.04-0.30-0.10=-0.64
Analisis Faktor dan variabel Laten
Didalam path analysis terkadang dijumpai istilah variabel laten dan variabel manifes. Variabel manifes adalah variabel yang secara kuantitatif dapat langsung diukur. Misalnya variabel pendapatan, biaya, kepuasan, dan lain lain. sedangkan varaibel laten adalah variabel yang secara kuantitatif tidak dapat dihitung, namun besarannya dapat ditentukan melalui group variabel manifes yang mendekatinya. Misalnya kita mengukur tentang kualitas komunikasi bisnis. Variabel tersebut tidak dapat diukur langsung. Tetapi diperoleh dari sekumpulan variabel manifes yang mencerminkan variabel kualitas komunikasi bisnis tersebut. Misalnya variabel banyaknya feedback, nilai kepuasan konsumen, delay waktu, ketepatan informasi dan lain lain.
Artinya, dalam penelitian atau survey, variabel laten ini kosong, belum ada data. Data diambil dari variabel variabel manifesnya. Pengelompokkan variabel manifes iniah yang biasa disebut sebagai analisis faktor.
Sebagian berpendapat bahwa adanya variabel laten inilah yang membedakan path dan SEM structural equation modeling nantinya. Menurut saya, dalam path analysis biasanya hanya ada satu variabel latennya karena path menjelaskan hanya satu jalur sebab akibat. Sedangkan pada SEM structural equation modeling, terdapat beberapa jalur path dan beberapa variabel laten yang menunjukkan hubungan antara variabel laten tersebut.
Sampai sini sudah jelas ya perbedaan antara regresi dan path analysis? Klo memang anda akan menggunakan path analysis, maka buat konsep dulu tentang variabel yang akan digunakan dengan teori teori yang ada. Kemudian dalam pembuatan kuesioner, minimal data yang akan diperoleh adalah data INTERVAL.
Terlebih bagi anda yang menanyakan tentang variabel mediasi, variabel mediasi memang boleh saja hasil perkalian antara dua variabel independen. Namun, jika anda melakukannya didalam regresi pasti akan terjadi multikolinear. Dan ingat, variabel dummy tidak bisa dilakukan kalkulasi perkalian untuk memperoleh variabel mediasi tersbeut. Jadi, sebaiknya gunakan variabel interval dan path analysis sebagai alatnya.
Baik, sekarang kita praktek langsung bagaimana mengolah path analysis. Saya punya data sebagai latihan bersama, silahkan diunduh:
Path analysis bisa menggunakan SPSS, namun kali ini saya menggunakan lisrel 8.8 karena di bagian bawah saya akan langsung menjelaskan tentang SEM structural equation modeling untuk data latihan yang sama.
Pertama buka software lisrel

Kemudian klik file – import data. Pilih file excel yang sudah di download diatas. File of typenya diganti dulu dengan csv agar file excelnya muncul di kotak windows. Klik open

Akan muncul save as. Silahkan save as dalam format asf dimanapun anda inginkan. Kemudian klik OK

Kemudian kita define variabel dengan cara klik data – define variabels. Akan muncul box windows kita pilih varoabel yang akan diubah atau select all, klik variable type. Pilih continous dan klik OK dan OK

Kemudian kita lanjutkan dengan screening data untuk mengetahui adakah kesalahan input data. Klik statistic – data screening. Biasanya akan minta save terlebih dahulu sebelum melakukan screening. Tunggu sebentar dan akan keluar hasil berupa analisis descriptive dari masing masing variabel.

Sebelum membuat path diagram kita uji normalitas untuk mengetahui sebaran data menyebar normal atau tidak untuk memenuhi persyaratan diatas. Klik statistic – normal scores. Dalam variabel list pilih semua, kemudian klik add.
Klik output option di box dialog yang sama, beri checklist pada perform tests of multivariate normality. Klik OK

Outputnya sebagai berikut

Lihat nilai p valuenya.. jika sudah lebih besar dari 0.05 artinya data sudah siap diolah (data menyebar normal). Jika p value masih leboh kecil dari 0.05 artinya data belum menyebar normal. Tentang uji normalitas akan saya jelaskan di artikel terpisah.
Kita simpan matrix korelasi atau koragam terlebih dahulu, klik statistik – output option, kemudian muncul box windows, moment matrix pilih covariance, beri centang pada save to file dan tentukan dimana anda akan menyimpannya. Sebaiknya jangan terlalu sulit karena alamatnya filenya akan ditulis manual di syntax. Klik OK

Dalam contoh ini saya akan menggunakan X4 X5 X6 dan X7 sebagai variabel manifes dari variabel laten yang saya beri nama komunikasi bisnis. Selanjutnya kita akan susun dalam simplis project
Klik file – new, pilih simplis project, klik OK. Otomatis akan meminta untuk save as, beri nama sesuai keinginan anda, klik save
Kemudian copy paste syntax pada file txt yang anda download diatas atau seperti ini:
Model CFA: komunikasibisnis
observed variables X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
Covariance Matrix from file D:/data1.cov
Latent Variables komunikasibisnis
Sample Size 100
Relationships
X4-X7 =komunikasibisnis
options: SS SC
Path Diagram
End of Problems
Model CFA merupakan singkatan dari Confirmatory Factor Analysis. Pada baris kedua merupakan alamat dimana anda menyimpan file covariance tadi (format “.cov”). kemudian klik run atau yang dilingkari merah

Maka hasilnya adalah:

Perhatikan bagian yang dilingkari merah, disana ada beberapa bagian. Gunakan standardized sollution untuk melihat nilai korelasi setiap variabel, dan gunakan T values untuk melihat signifikansi setiap korelasinya. Biasanya korelasi yang tidak signifikan akan otomatis berwarna merah pada T valuenya.
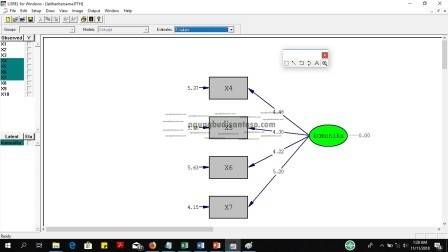
Gambar diatas adalah nilai T values maisng masing korelasinya.
Bagaimana jika saya tidak mau menggunakan varaibel laten? Tetapi menggunakan variabel yang ada. Anggap saja variabel X5 sebagai variabel dependen dari variabel X1 hingga X4.
Kemudian X7 merupakan variabel dependennya dari X5 dan X6, atau bisa dinotasikan
f(X5) = (X1, X2, X3, X4)
f(X7) = (X5, X6)
caranya sama dengan diatas, hanya menggunakan syntax yang agak berbeda pada barisan relationship yakni menjadi:
Model CFA: komunikasibisnis
observed variables X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
Covariance Matrix from file D:/data1.cov
Sample Size 100
Relationships
X5 =X1-X4
X7 =X5-X6
options: SS SC
Path Diagram
End of Problems
Hasilnya adalah:
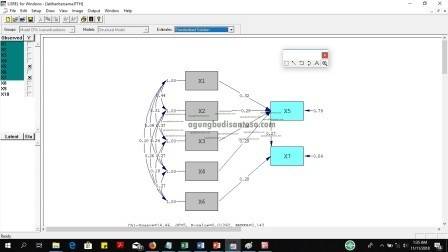
Gambar diatas untuk nilai korelasinya

Untuk nilai signifikansinya, terlihat beberapa diantara warna merah yang artinya tidak signifikan.
Penjelasan output sudah saya jelaskan diatas, jadi silahkan bereksplorasi tentang hubungan masing masing X ke X7.
Structural Equational Modeling
Seperti yang sudah saya jelaskan sebelumnya bahwa perbedaan SEM structural equation modeling dilihat dari struktur diagramnya lebih kompleks dan lebih dalam dibandingkan path analysis. Jadi dalam Sem bisa terdapat persamaan regresi yang lebih dari 2 yang digambarkan dalam sebuah model yang saling terintegrasi.
Dalam SEM structural equation modeling variabel laten terbagi menjadi 2 yakni variabel endogenous dan eksogenous. Variabel eksogenous adalah variabel yang tidak ditentukan variabel lain dalam model (hampir sama dengan pengertian independen variabel). Dalam sem variabel eksogenous ditunjukkan dengan variabel yang memiliki arah panah keluar. Sebaliknya, variabel indogen memiliki panah kedalam, yang berarti nilai variabelnya dipengaruhi oleh variabel lain.
Perlu ditekankan bahwa SEM structural equation modeling merupakan pendekatan yang terintegrasi antara analisis data empirik dengan pengembangan konsep teoritik. Jadi sebelum membuat model, perlu adanya dukungan teori yang kuat yang kemudian teori tersebut dibuktikan dengan data empiris di lapangan.
Mengenai teori dan rumus rumusnya silahkan anda membaca buku text tentang SEM. Artikel ini saya buat untuk mencatat langkah teknis dalam software. Mari Langsung saja kita praktek. Data yang digunakan masih sama dengan data yang digunakan di Path. Langkah import sampai dengan save covariance sama dengan langkah path diatas. Yang membedakan adalah syntax yang kita tuliskan dalam sofware.
Seperti yang disebutkan diatas, pembuatan model SEM structural equation modeling perlu didasarai oleh teori. Saya asumsikan disini bahwa model yang akan saya buat sudah memilii teori. Karena ini hanya latihan, tentu saja variabel dalam contoh ini adalah data random yang saya buat sendiri.
Saya mengasumsikan bahwa terdapat variabel laten trust terdiri dari variabel X1 sampai X3, kemudian variable satisfaction terdiri dar variabel X4 sampai X7. Loyalti dipengaruhi oleh variabel trust dan satisfaction yang juga dipengaruhi oleh X8 hingga X10. Kurang lebih notasinya seperti ini:
f(trust) = (X1, X2, X3)
f(satisfaction) = (X4, X5, X6,X7)
f(loyalti) = (X8, X9, X10, trust, satisfaction)
Dalam hal ini variabel laten endogen adalah loyalti, sedangkan trust dan satisfaction adalah laten eksogen.
Syntax SEM structural equation modeling kurang lebih seperti ini
model sem
Observed variable X1 X2 X3 X4 X5 X6 X7 X8 X9 X10
Covariance matrix from file D:\data1.cov
Latent variables satisfaction loyalty trust
Sample size 100
Relationships
X1-X3 = trust
X4-X7 = satisfaction
loyalty = trust satisfaction
X8-X10 = loyalty
Lisrel Output: SS SC
Path Diagram
End of Problem

Hasilnya akan seperti ini

Anda bisa mengubah model dengan beberapa jenis seperti X model, Y model, structural model, basic dan correlated error. Model yang biasa di pertunjukkan adalah basic model. Nilai T value dan nilai korelasinya juga bisa dilihat di bagian estimates.
Tentang pembuatan model, saya asumsikan anda sudah bisa membacanya ya… karena path diagram sangat mudah dibaca. Perhatikan saja arah panah dalam membuat persamaannya, dengan nilai di panah itu adalah koefisien variabel independennya. Sedangkan menghitung total pengaruh sudah saya jelaskan diatas.
Goodness of Fit
Pertanyaannya adalah apakah model ini bisa menunjukkan atau bisa digunakan untuk mewakili kondisi sebenarnya? Maka kita perlu melihat kriteria kriteri model dan menentukan layak atau tidak. Beberapa kriteria yang digunakan dalam menentukan model ini layak atau tidak adalah Chi-square, RMSEA, GFI, AGFI, CFI, dan AIC.

Model yang baik memiliki nilai chi square tidak berbeda jauh dengan derajad bebasnya. Hal ini berhubungan dengan jumlah datayang digunakan dalam penelitian. SEM structural equation modeling akan lebih baik menggunakan data diatas 100
RMSEA atau Root Mean Square Error of Approximation akan baik apabila berada kurang dari 0.05. Dari kepanjangannya sudah tau ya apa itu RMSEA? Yup, isinya menunjukkan tingkat error.
GFI atau Goodness of Fit Index menunjukkan tngkat kebaikan suatu model menjelaskan data. Ini mirip sekali dengan R squared. Jadi akan lebih baik jika nilainya mendekati 1.
AGFI atau Adjusted Goodness of Fit Index biasa deisebut R squared adjusted jika di regresi. Penjelasan perbedaan r square dan r squared adjusted sudah saya jelaskan di artikel yang berjudul : Apa perbedaaan R Squared, R squared adjusted, dan R Squared Predicted
CFI atau Comparative Fit Index merupakan nilai dari 0 sampai 1. Kekuatan CFI ini adalah tidak sensitif terhadap besar sample. Jadi bisa digunakan untuk membandingkan model atau penelitian yang lain meskipun berbeda jumlah sample. Karena, semakin besar sample biasanya mempengaruhi GFI dan AGFI.
AIC atau Akaike Information Criterion digunakan untuk membandingkan model yang dalam SEM yang menjelaskan data. Pilih model yang memiliki AIC paling kecil.
Jika dilihat hasil output kebaikmodelan dari latihan kita, hal yang masih perlu diperbaiki adalah bagian chi square karena terlalu jauh dengan nilai derajad bebasnya. Lalu bagaimana cara memperbaikinya? Insha allah saya jelaskan di artikel yang berbeda.
Kali ini tugas saya untuk mencatat bagaimana proses membuat model path analysis dan SEM structural equation modeling.
Selamat Belajar..!
Jangan lupa share..
Permisi pak, jika saya menggunakan SEM sebagai alat alanilis untuk mengetahui hubungan antara variabel X dan variabel Y dengan variabel Z sebagai mediasi. bisakah bapak memberikan saya rekomendasi mengenai uji apa saja yang perlu saya gunakan? terimakasih
Saya sudah pernah mengulas sem. Silahkan gunakan pencarian di blog ini.
Assalamualaikum wr.wb. Permisi Bapak izin bertanya beberapa pertanyaan:
1. Apakah path analisys memerlukan uji asumsi klasik, jika iya uji apa saja yang perlu dilakukan.
2. Jika seandainya uji normalitas terhadap data dinyatakan tidak terdistribusi normal, maka uji apa yang cocok digunakan untuk melihat hubungan antar variabel pada model path analisys tersebut.
3. Apakah Bapak memiliki rekomendasi buku atau modul ajar yang bisa untuk saya beli dan pelajari untuk dua masalah tersebut.
Terima kasih atas jawaban yang Bapak berikan.
wa alaikum salam wr. wb
tolong dipahami bahwa uji asumsi klasik itu hanya ada untuk OLS. OLS tidak menggunakan iterasi sehingga dibutuhkan uji uji tersebut. sedangkan path analisis sepengetahuan saya menggunakan Maximum Likelihood, jadi tidak membutuhkan uji asumsi klasik.
terima kasih
Ingin tanya pak, apa perbedaan analisis regresi hirarkikal dan path analysis? karena pemahaman saya hampir mirip. Apakah hanya perbedaan pada path analysis yang tidak memperhitungkan uji multikolinearitas saja?
klo dijabarkan rumus, path tidak memiliki konstanta pada persamaannya.
Permisi pak saya mau bertanya. penelitian saya itu pengaruh x terhadap y dengan 2 variabel mediasi dan 2 varibel moderasi. apakah model penelitian seperti itu bisa dianalisis dengan regresi berganda? Terimakasih pak, mohon bantuannya
Bisa di jelaskan, jika penelitian menggunakan sem, namun perlu dilakukan pengujian thdp beberapa responden sbg penelitian awal, apakah bs dilakukan lgsg menggunakan sem?
Jika data yang digunakan skala likert, maka sebaiknya memang didahului uji validasi dan realibilitas karna itu melekat kepada pengujian alat. Terima kasih
Halo tolong jawab ya karena saya sedang membutuhkan jawaban, apakah di regresi juga harus endogenous dan ekstrogenous ?
endogenous dan eksogenous ada di regresi tapi dibahas dalam persamaan simultan.
Selamat malam mau bertanya
perbedaan confirmatory analysis dan pengaruh dasar apa ya pak?
selamat siang.. cara singkat membedakan keduanya adalah saat berbicara confirmatory analysis seolah kita membicarakan secara makro. asumsi ols dan asumsi asumsi pada dasar korelasi sementara diabaikan. sedangkan penngaruh dasar di artikel ini merujuk kepada hubungan regresi yang mensyaratkan berbagai macam asumsi yang harus dipenuhi karena menjadi tolok ukur sebuah sebab akibat. terima kasih
Selamat Pagi,
pak saya ingin bertanya prihal perbedaan Path Analisis, SEM PLS dan SMART PLS?
Dapatkah bapak memberikan pencerahan kepada saya?
Selamat sore. Terima kasih atas masukannya. Suatu saat insha allah akan saya bahas.
pak apa persamaan khusus dari path analysis dengan sem ?
pak saya mau bertanya jika di penelitian hanya ada variabel independen (x) dan dependen (y) (di penelitian saya memakai variabel independennya 3 dan 1 variabel dependen) tanpa ada variabel intervening atau moderasi apa masih tetap bisa digunakan analisis path?
Kenapa tidak menggunakan regresi?
pakai path karena saya ingin mencari tau berapa besaran pengaruh langsung dan tidak langsungnya tanpa variabel intervening. saya menemukan referensi dari http://www.jonathansarwono.info/aj/analisis_jalur.htm yang mencontohkan tanpa adanya variabel intervening bisa menggunakan path analysis model regresi linier berganda. menurut bapak apakah referensi tersebut benar atau tidak, saya butuh pendapatnya pak karena masih tidak yakin..
bisa, tapi karna path sifatnya explanatory, jadi hasilnya tidak bisa dijadikan sebagai model nantinya. jika hanya menemukan hub langsung dan tidak langsung, silahkan saja menggunakan path.
namun sebenarnya dalam kasus yang sangat sederhana tersebut, anda bisa menggunakan regresi saja untuk hub X dengan Y. sementara hubungan sesama X anda bisa menggunakan korelasi. adapun gambar sistemnya nanti tetap sama. terima kasih
Assalamualaikum.. pak.mohon info. Path analisis disarankan data minimal berbentuk interval. Dasar dari pernyataan ini bisa diambil dr referensi mana? Terima kasih
wa alaikum salam.. kata disarankan disana ga harus ya mas.. karna sy perhatikan data ordinal pun ada yang bisa diolah path analisis. data interval mengacu karena alat analisis ini termasuk dalah parametrik method. silahkan lihat di buku Latent Variable Models: An Introduction to Factor, Path, and Structural Equation Analysis. terima kasih
halooo ka, apa saya boleh tanya-tanya ? kebetulan penelitian skripsi saya juga menggunakan 3 variabel independen dan 1 variabel dependen tanpa ada variabel intervening. kalo diperbolehkan untuk bertanya-tanya, saya minta emailnya ya, terimakasih
maaf baru balas. untuk menghubungi saya cukup lewat blog ini aja mbk..
https://agungbudisantoso.com/contact-me/
terima kasih
apa perbedaan antara SEM dengan CFA ?
semua orang terlahir unik dan pasti berbeda. heheheheh
Selamat pagi…
Mau tanya, adakah filenya pak modul pengantar tentang SEM
Selamat siang. Ada tapi maaf, saya tidak memiliki izin menyebarkan langsung. Jadi memang sudah saya tulis ulang di artikel ini.
permisi numpang nanya tadi diatas ada disampaikan bahwa untuk menggunakan path analysis itu biasanya hanya memiliki 1 variabel laten. Apabila dalam suatu model penelitian seperti dibagian path analysis tersebut malah semuanya menggunakan variabel laten apakah masih boleh digunakan metode path ini?
Selamat sore.. bisa dibedakan jika sem variabel dependennya variabel laten. Tapi klo variable latennya masing masing berdiri sendiri, masih pakai path karna tidak menjelaskan hub satu sama lain antara variabel laten. Jadi jika pertanyaannya hanya bbrp variabel laten saja sih masih bisa pakai path. Penjelasan diatas saya menggunakan kata “biasanya” satu variabel laten
Permisi pak, saya mau tanya. Jadi penelitian saya itu pengaruh X terhadap Y dengan 2 variabel moderasi. Nah untuk pengaruh X terhadap Y kan saya gunakan regresi sederhana, kemudian untuk variabel moderasinya apakah pake Moderated Analysis Regression atau yg mana ya pak? Terimakasih
hati hati dengan variabel moderasi mbk. karna resiko multikolinearitasnya sangat besar. untuk mengetahui kekuatan moderasi sebuah variabel sebaiknya menggunakan path analysis. bisa dibaca artikel saya yang berjudul perbedaan regresi, path dan sem. terima kasih
Permisi pak, saya mau tanya. saya melakukan percobaan dengan 1 variabel independent, dependent dan moderating. saya melakukan percobaan dengan langkah-langkah seperti yang bapak tulis.
saya kesulitan waktu melakukan pengaruh moderasi dengan variabel independent terhadap variabel dependentnya pak. untuk Simplisnya itu bagaimana ya pak? soalnya saya melakukan perkalian di simplis tetapi error dan tidak bisa pak. ataupun terdapat kode simplis yang harus ditambahkan atau bagaimana pak? mohon izin petunjuknya pak
buat variabel baru yang menjadi moderatingnya di excel terlebih dahulu. terima kasih