Variabel dummy dalam regresi sedikit berbeda dengan variabel lainnya baik dalam pengolahan data ataupun saat membaca hasil regression. Regresi linear atau regresi berganda merupakan suatu fungsi yang menjelaskan hubungan varaibel independen dengan variabel dependen. Satu variabel dependen (Y) biasanya dipengaruhi oleh beberapa varaibel independen (X). misalnya variabel produksi dipengaruhi oleh luas lahan, pupuk, jumlah tenaga kerja, modal.
Regresi memiliki beberapa persyaratan yang harus dipenuhi. Karena regresi masuk dalam statistik parametrik, tentunya variabel-variabel didalamnya memiliki skala interval atau rasio. Selain itu data-data yang akan digunakan juga harus memenuhi kaidah asumsi klasik. Tetapi, dari beberapa variable yang kita gunakan, bisa saja satu atau dua variabel tersebut berupa variabel dalam skala nominal atau ordinal. Variabel skala nominal atau ordinal di dalam regression tersebut biasa dikenal sebagai variabel dummy.
Agar lebih gampang dipahami, saya berikan contoh variabel dummy dalam regression. Misalkan saja kita ingin mengetahui pengaruh jenis kelamin terhadap pendapatan yang dibelanjakan ke mall. Kita buat variabel jenis kelamin dengan nilai 0 untuk laki-laki dan 1 untuk perempuan. Contoh lain, pengaruh keikutsertaan petani dalam keanggotaan kelompok tani terhadap pendapatan. Kita buat variabel keikutsertaan kelompok tani dengan nilai 0 untuk petani yang tidak menjadi anggota, dan 1 untuk petani yang menjadi anggota kelompok tani.
Variabel dummy dalam regresi berbeda dengan regresi logistik. variabel skala nominal di regresi logistik terletak di variabel dependen atau nilai Y. sedangkan dummy yang dimaksud disini adalah variabel skala nominal atau ordinal pada variabel independen (nilai X). bisakah dummy di dalam regresi logistik? jawabannya tentu saja bisa.
Pemberian nilai 0 dan 1 juga memiliki tehnik tersendiri. Agar mudah dalam menginterpretasikan hasil output regression, sebaiknya nilai 1 diberikan kepada responden yang diharapkan memiliki pengaruh terhadap nilai Y. Misalnya contoh keanggotaan petani diatas, saya memiliki hipotesis bahwa keanggotaan ini memilikipengaruh terhadap pendapatan petani. Sehingga saya memberikan nilai 1 terhadap petani yang menjadi anggota kelompok tani. Karena nanti hasil koefisien pada variabel ini merupakan pembeda antara petani yang tidak menjadi anggota dan petani yang menjadi anggota kelompok tani. Jika anda memberi nilainya terbalik, sebenarnya tidak ada yang salah, namun besar kemungkinan nilai koefisien yang keluar nantinya bernilai negatif. Tidak ada yang salah dengan hasil perhitungan tersebut, hanya saja anda perlu mengerti cara menjelaskan nilai negatif tersebut.
Saya akan langsung praktekkan penggunaan variabel dummy dalam regresi di aplikasi minitab.
Saya memiliki data latihan yang bisa diunduh disini:
Data tersebut merupakan data rekayasa yang secara random saya peroleh melalui excell. Terdapat 5 variabel independen, dimana salah satunya yakni variabel X2 merupakan variabel dummy dalam regression.
Mari kita buka minitabnya. Saya menggunakan minitab 17.
Kita masukkan datanya di sheet minitab

Kemudian klik stat – regression – regression – fit regression model

Responses kita masukkan variabel Y, continous preditors kita masukkan X1, X3, X4, X5. Sedangkan variabel X2 yang merupakan variabel dummy dalam regression kita masukkan ke categorical predictors

Klik Ok dan tunggu hasilnya..

Terlihat dari model summary, nilai R-sq pada model memiliki nilai 65.09% artinya bahwa 65% data yang diolah mampu dijelaskan oleh model hasil minitab tersebut. Bisa dikatakan bahwa model ini cukup untuk merepresentasikan data yang ada.
Dilihat dari nilai p value, diantara kelima variabel hanya X2 yang memiliki nilai dibawah 0.05. artinya hanya x2 yang signifikan mempengaruhi nilai Y. dilihat dari nilai VIF, variabel X1 dan variabel X4 memiliki nilai diatas 10, artinya kedua variabel tersebut memiliki masalah multikolinear (sudah saya bahas di uji asumsi klasik).
Asumsi saya bahwa output diatas sudah dibenahi sesuai uji asumsi klasik, saya akan menjelaskan output variabel dummy sesuai tema artikel kali ini.
Pada kolom koeffisien nilai 1 pada variabel X2 memiliki nilai 3876. Artinya bahwa responden yang memiliki nilai 1 secara signifikan memiliki 3876 Y yang lebih tinggi daripada responden yang bernilai 0. Hal ini juga bisa diperoleh dari regression equation pada bagian paling bawah, yakni sbb:

Nilai model regresi saat X2 bernilai 0 adalah : 5468 + 2.89X1 – 19.0X3 – 5.74X4 – 1.49X5. sedangkan model regressi saat X2 bernilai 1 adalah : 9344 + 2.89X1 – 19.0X3 – 5.74X4 – 1.49X5. nilai koefisien 3876 diperoleh dari selisih kedua model tersebut dengan asumsi X1, X3 X4 dan X5 memiliki nilai yang sama.
Sehingga dapat disimpulkan variabel X2 yang bernilai 1 memiliki nilai Y 3876 lebih tinggi daripada variabel X2 yang bernilai 0.
Pahami perbedaan pembacaan koefisien regression lainnya. Karena jika variabel tersebut merupakan variabel continous atau skala interval dan rasio, maka koefisien variabel akan dibaca setiap tambahan satu satuan variabel independen akan meningkatkan variabel dependen sebesar nilai koefisien.
Beda minitab, beda pula SPSS. Saya juga berikan langkah di SPSS karena SPSS juga banyak digunakan. Pada SPSS variabel skala nominal dan ordinal sudah dipisahkan sejak pertama kali diinput, sedangkan prosesnya sama seperti anda melakukan regresi berganda atau linear. SPSS akan mengenali variabel dummy tersebut setelah anda memberi keterangan bahwa variabel tersebut berskala nominal.
Mari kita buka SPSS, kemudian copy data ke sheet spss

Pada tab variabel view, saya menandai keterangan pada X2 bahwa variabel tersebut adalah variabel dummy atau berskala nominal. Erhatikan di tabel measure pada gambar dibawah ini

Kemudian klik analyze – regression –linear. Kemudian masukkan Y pada kolom dependen, dan semua variabel X ke dalam kolom independen dan klik OK

Hasilnya adalah sebagai berikut
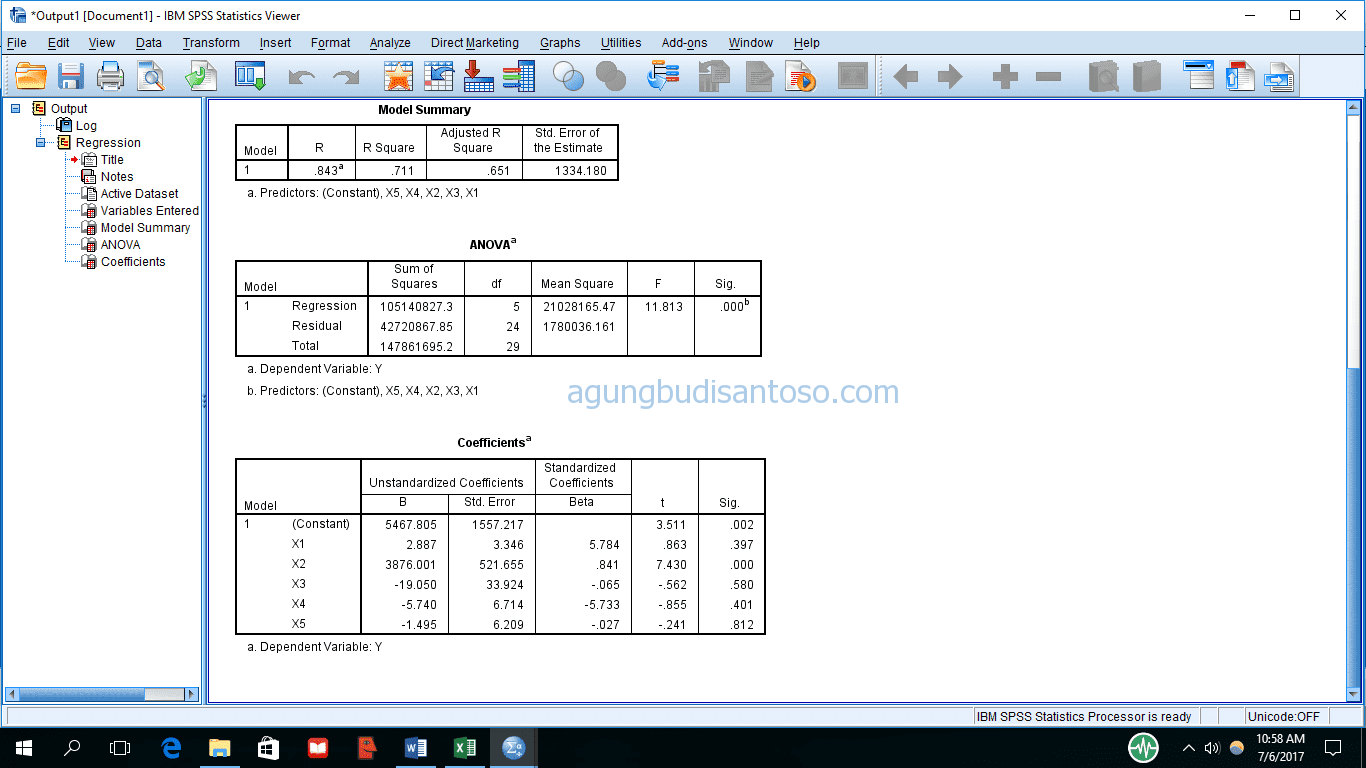
Hasil yang diperoleh sama dengan hasil yang dikeluarkan oleh minitab. Nilai koefisien bisa anda lihat di tabel koefisien pada kolom B dengan nilai 3876. Namun, SPSS tidak menyediakan model untuk kedua nilai pada X2 seperti yang dikeluarkan oleh minitab.
Sekian dan terima kasih sudah berkunjung.
note: dikarenakan dummy adalah data yang bersifat ordinal atau nominal, biasanya model yang dihasilkan pada regresi memiliki error yang cukup tinggi. maka ada baiknya anda juga memahami bagaimana cara menghitung error model regression tersebut dengan menyimak video di artikel ini.
silahkan temukan video lain terkait regresi pada laman video tutorial di menu blog ini.
Selamat sore pak, apabila variabel dummy saya semuanya 0 dan yang memiliki angka 1 hanya dua apakah masih bisa?
sepertinya sulit. tidak imbang dan asumsi klasiknya susah terpenuhi
Assalamualaikum wr.wb. Izin bertanya pak. penelitian saya mencari tahu keefektifan kebijakan kerja sama yang dilakukan oleh pemerintah. Jumlah perjanjian (x) dan terlaksananya perjanjian (y). Kemudian saya menggunakan regresi nominal, untuk membedakannya, jumlah perjanjian (x) menggunakan angka 0 dan terlaksananya perjanjian (y) menggunakan angka 1. Apakah bisa seperti itu pak dan langkah selanjutnya saya harus bagaimana ya pak?
wa alaikum salam. saya masih tidak paham. X nilainya 0 dan Y nilainya 1? artinya semua nilai dalam variabel x nilainya 0 dan semua nilai Y nilainya 1?
sepertinya ada yang salah, atau saya yang salah baca mbak?
Selamat pagi pak, saya melakukan penelitian menggunakan regresi logistik, selain variabel X dan Y ada variabel Z (moderasi). Apakah variabel moderasi boleh dalam bentuk dummy dalam regresi logistik yang Y nya juga sdh dalam bentuk data dummy?
Terima kasih
assalamualaikum pak, izin bertanya pak penelitian saya menguji pengaruh likuiditas dan leverage terhadap financial distress (dummy) dengan ROA sebagai variabel moderasi, apakah nanti dalam pengujian regresi logistik variabel moderasi ini dimasukan atau tidak ya pak?🙏🏻
Wa alaikum salam..iya, variabel moderasinya dimasukkan untuk mengetahui peran moderasi variabel tersebut. Tapi perlu dicoba model yang lain (menghilangkan moderasi) dan kemudian membandingkan model model tersebut.
punten pak saya sudah coba tapi hasil sig. hosmer & lemeshownya 0,058 apakah layak atau tidak ya pak? lalu sebaiknya hrs bagaimana ya pak? sedangkan jika variabel moderasinya tidak dimasukkan nilai sig. nya < 0,05 🙏🏻 terima kasih
Maaf pak agung izin brtanya..dlm uji asumsi klasik idealnya penggunaan variabel dummi maksimal berapa ya supaya tidak kesulitan dalam pengerjaannya?
Upayakan perbandingan dummy dengan continous variabel tidak lebih 1 berbanding 2. jawaban saya ini tidak ada dasarnya, hanya berbekal pengalaman saya mengolah data. Terima kasih.
Permisi pak saya mau tanya, penelitian saya menggunakan skala rasio untuk variabel independennya, sedangkan variabel dependennya adalah dummy, dosen pembimbing saya mengatakan kalau variabel dummy tersebut perlu dirubah ke rasio, apakah bisa pa? caranya bagaimana ya pa?
pemahaman saya data yang bisa dikonversi adalah rasio ke nominal (dummy adalah nominal), bukan sebaliknya. misal, data pendapatan bisa kita kelompokkan menjadi pendapatan kecil dan pendapatan besar. namun klo data awalnya adalah data nominal (cuma pilihan pendapatan kecil dan besar), bagaimana mengkonversinya menjadi rasio?? mungkin maksud dosennya mengganti variabel dengan variabel yang berskala rasio. terima kasih.
Pagi pak, izin bertanya, kebetulan penelitian awal saya Var. Dependen adl F-Score yg merupakan variabel dummy diolah menggunakan regresi logistik, namun jarna hasilnya tidak bagus dosen menyarankan utk ganti ke linier berganda, hasilnya memang lebih baik. tapi dr dosen menyarankan saya utk mencari alasan ilmiah (tidak disarankan menggunakan alasan hasil penelitian tidak baik) knp variabel dependen dummy diolah menggunakan regresi linier berganda. Terima Kasih
selamat pagi.. silahkan identifikasi menggunakan grafik regresi untuk melihat apakah benar kecenderungan model yang tepat digunakan dengan linear (regresi berganda), bukan dengan s slope (regresi logistik). cara membuat grafik regresi sudah saya praktekkan di https://youtu.be/-z6WFz9NbR8 . terima kasih
Assalamualaikum pak izin bertanya. Saya akan menguji dummy pada Var Independen dan Skala Rasio pada var Dependen. Untuk variabel dummy pada variabel independen bentuk transformasi apa yang dibutuhkan seperti halnya MSI pada skala ordinal? apakah variabel dummy memerlukan transformasi/pengubahan skala data? terimakasih sebelumnya
wa alaikum salam .. dummy itu skalanya nominal, antara ya atau tidak, antara laki laki atau perempuan, dll. sebenarnya sangat disayangkan jika ada variabel dengan skala rasio kita konversi menjadi dummy. tapi jika terpaksa karna akan menguji dua kelompok, otomatis diperlukan transformasi pengubahan data. terima kasih.
Assalamualaikum pak, kalau data dummy saya 0 semua itu gimana ya? Apa masih bisa kalau dilakukan uji asumsi klasik dan regresi?
Wa alaikum salam. Ketika kita membuat dummy 0 dan 1, artinya kita menyiapkan dua kelompok, dan itu harus terisi datanya. Karna akan percuma jika hanya satu kelompok saja, alat apapun tidak bisa melakukan pembedaan pada dua kelompok jika tidak ada wakil dari kedua kelompok. Solusinya ada dua, melengkapi kelompok dummy yang tidak ada, atau menghilangkan variabel dummy. Terima kasih
Assalamualaikum, saat ini saya sedang menyusun skripsi dengan jumlah 1 variabel dependen, 3 variabel independenden dan 4 variabel dummy. Pada awal2 data masi bisa diregres tp saat dicoba lagi mengapa datanya tidak dapat diregres. Alasannya kenapa ya pak. Terimakasih
Wa alaikum salam… Jika lihat komposisi variabel independennya, sepertinya variabel dummynya terlalu banyak.. coba mampir ke channel youtube catatan budi, video berjudul. “Fatal, jangan regresikan data..”
Terima kasih
izin bertanya, saya berencana melakukan penelitian tentang pengaruh pengetahuan (X1), religiusitas (X2), dan persepsi (X3) terhadap minat (Y) melakukan wakaf. untuk data variabel X didapat melalui kuesioner berupa skala likert dengan beberapa butir pertanyaan pada tiap variabel. dan untuk variabel Y menggunakan dummy 1= berminat 0= tidak berminat. Apakah bisa dilakukan regresi probit pada data tersebut. terima kasih
saran saya variabel independennya ditambah lagi beberapa variabel yang sifatnya rasio seperti pendapatan atau lama pendidikan. terima kasih
Selamat siang Pak.
Saya ingin bertanya, apabila variabel independen dan 2 variabel moderasi menggunakan dummy, sedangkan variabel dependen menggunakan rasio maka analisis yang tepat menggunakan regresi linier atau logistik?
Dan apakah penggunaan dummy pada 3 dari 4 variabel akan berpengaruh terhadap penelitian saya?
Terima kasih.
Selamat pagi pak, izin bertanya apabila saya menggunakan variabel dependen yang harus menggunakan dummy seperti misalnya pemilihan metode persediaan jika dinominalkan maka FIFO = 0 dan Average = 1, apakah saya masih bisa menggunakan regresi linear berganda atau saya harus menggunakan regresi logistik untuk mengujinya pak? Terimakasih banyak
kata kuncinya di variabel dependen . berarti menggunakan regresi berganda. terima kasih
Halo selamat siang,
Izin bertanya data dummy saya 1 semua.
Apa ada solusi untuk hal ini? Terimakasih🙏
tidak ada solusi. anda harus mencari responden dengan dummy nilai 0 agar bisa diproses ya.. terima kasih
Assalamualaikum warahmatullahi wabarakatuh.
Mohon izin bertanya bapak, bisakah variabel independen dengan dummy digunakan untuk regresi linear? Saya sedang meneliti mengenai wtp dan memiliki 5 variabel independen. dari kelima variabel tersebut terdapat 3 variabel yang dummy. Saya sudah mencoba meregresi dengan regresi linear namun r square nya rendah sekali sebesar 0.040.
Mohon arahan dan bimbinganya bapak. Bagaimana cara menaikan r square tersebut. Apakah karna variabel dummy yang saya gunakan terlalu banyak sehingga hasil r square nya rendah.
Iya..benar. proporsi dummynya terlalu banyak. Bagaimana pun regresi linear adalah data parametrik. Jadi untuk 5 variabel mungkin hanya 1 yang bisa ditambahkan dummy. Terima kasih
Assalamialaikum wr wb pak
Saya mau bertanya kira kira di dalam menggunakan variabel dummy pada variabel independen itu apakah ada batasannya, misalkan saya menggunakan regresi logistik dengan variabel dependen yang dummy, dan 5 variabel independen, apakah saya bisa meletakan 2 variabel dummy di variabel independen? Terima kasih
belum ada yang menjelaskan batasan dari variabel dummy yang digunakan, namun biasanya akan berdampak pada hasil dan asumsi klasiknya. berapapun variabel dummy yang digunakan jika asumsi klasik semua memenuhi syarat dan hasilnya bagus, maka tidak masalah. hanya saja, karena regresi adalah tools untuk data continous maka sebaiknya komposisi data yang berskala rasio lebih banyak dibanding dummy. saya rasa 2 dummy dari 5 variabel masih OK untuk diteruskan. terima kasih
Aswr. Makasih banyak sharingnya.
Izin bertanya , saya ingin mereplikasi satu jurnal Q2. jurnal tersebut meneliti social capital (X) dan pengaruhnya terhadap mobilitas (Y). Data mobilitas di tahun 2020, sementara pengklasifikasian social capital menjadi kategori dummy (tinggi =1, rendah =0) menggunakan data di tahun 2005. Apakah perbedaan waktu ini justified secara ilmiah? Terima kasih banyak. Salam
Wa alaikum salam.
Jika mas bisa membuktikan bahwa kondisi hub kedua variabel tersebut tidak dipengaruhi oleh waktu terutama tahun 2020 dan 2005 maka bisa dijustifikasi. Maksud disini ada kondisi cateris paribus.
Terima kasih
saya meneliti tentang pengaruh pandemi terhadap penjualan UMKM, dimana hasil tersebut menunjukan bahwa hasil coefficient dummy Covid19 saya (-) artinya pandemi menyebabkan penurunan pada penjualan UMKM. Namun untuk membandingkan besaran antara angka 0 = tidak terdampak pandemi covid19 dan 1= terdampak pandemi covid19 itu mengalami besaran yg dimana lebih besar angka dummy 0 dibandingkan 1 karena coefficient nya (-), itu bagaimana ya pak menjelaskannya? Yang saya harapkan adalah UMKM yang terkena dampak dari Pandemi Covid19 disimbolkan dummy 1 harusnya mempunyai besaran lbh tinggi, namun terjadi sebaliknya . Mohon bantuannya pak 🙏🏻
Ceritanya belum lengkap. Coba tambahkan apa variabel y dan apa sja variabel xnya. Termasuk apakah ini regresi logistik atau berganda?
Tapi dugaan saya mungkin kesalahan metode sampling. Terima kasih
Asalamuallaikum, ada yg ingin saya tanyakan salah satu variabel dummy dalam skripsi saya adalah opini audit, dimana nilai 1 untuk perusahaan yang mendapat opini audit wajar tanpa pengecualian dan nilai 0 untuk sebaliknya. Ketika pra riset ternyata nilai variabel dummy saya 1 semua. Apakah masih bisa di lakukan uji?
wa alaikum salam.. tidak bisa.. tidak akan valid datanya. terima kasih
Terimakasih— materi yang bermanfaat, semoga menjadi amal baik p. Agung
mau nanya lagi, variabel y saya ini pengungkapan csr, cara mengetahuinya dengan angka 1 untuk mengungkapkan 0 untuk tidak dan ada rumusnya dimana jumlah total yang diungkapkan dibagi dengan jumlah itemnya. contoh yang diungkapkan 50 jumlah item 91 jadi (50/91) nah pertanyaannya ini skala pengukurannya apa ya apakah rasio atau nominal dan pengujianya apakah menggunakan regresi berganda atau logistik, terimakasih
silahkan browsing tentang regresi tobit. tapi saya belum membahas khusus di blog saya. terima kasih
jadi apakah boleh menggunakan variabel dummy lebih dari 1 dalam sebuah penelitian. misal ada 4 variabel x ada 2 variabel dummynya. dan apa nanti pengaruhnya saat dalam pengujian di regresi.
terimakasih
boleh. konsekuensinya jika anda menggunakan banyak variabel dummy, uji asumsi klasik akan tidak terpenuhi. terima kasih
Apakah dengan independen berupa dummy dan dependen juga berupa dummy bisa diolah dengan regresi logistik?
Bisa… Regresi logistik dengan variabel independennya juga dummy. Terima kasih
Apa beda variabel dummy dengan variabel moderasi
Variabel dummy gambarannya adalah variabel independen yang berpengaruh langsung terhadap variabel dependen. Skalanya hanya nominal.
Variabel moderasi gambarannya adalah variabel independen yang berpengaruh langsung dan bisa menjadi jembatan atau penghubung bagi variabel independen lain yang berpengaruh tidak langsung terhadap dependen variabel.
Skalanya bisa nominal sampai rasio.
Terima kasih
Selamat pagi pak, izin bertanya. Saya sedang melakukan penelitian skripsi dengan regresi logistik karna y saya merupakan variabel dummy. Saya menggunakan 5 variabel x (3 rasio dan 2 dummy) dan 1 variabel moderasi (rasio). Dalam skripsi saya, variabel moderasi digunakan langsung pada 5variabel x saya pak. Yang ingin saya tanyakan, apakah bisa dilakukan perhitungan var moderasi apabila saya memiliki 2 var x dengan skala dummy?
dummy sebaiknya tidak digunakan moderasi. karna akan menghabiskan variabel lainnya yang mungkin bukan dummy. bayangkan saja, variabel dengan skala rasio akan berubah menjadi dummy karena moderasinya dummy. sayang kan?
Assalamualaikum, pak.
Saya sedang melakukan tugas akhir skripsi dalam bidang manajemen keuangan, dengan profitabilitas sebagai variabel X (rasio), nilai perusahaan sebagai variabel Y (rasio), dan kebijakan dividen sebagai variabel intervening (dummy). Pada uji normalitas data saya tidak normal, kemudian saya transformasi lg10 menjadi normal (pada uji normalitas variabel dummy ini tidak diikut sertakan).
Pertanyaan saya yaitu pada uji asumsi klasik selanjutnya (multiko, hetero, autokorelasi, dan linearitas) apakah variabel dummy ini di transform juga atau tidak yah pak?
Menggunakan data yang sudah valid pada uji sebelumnya. Jika diuji normalitas ditransform, maka uji asumsi klasik yang lainnya pun menggunakan data yang telah ditransform. Terima kasih
Pada mengobati uji autokorelasi, apakah variabel dummy ikut di transform cochrane orcutt juga atau tidak yah pak?
apakah ada yang dapat menjawab pertanyaan ini? akan sangat membantu. terima kasih
Pertanyaan lanjutan saya adakah buku referensi yang bisa saya gunakan sebagai rujukan untuk melakukan regresi linier sederhana dengan salah satu variabel dummy dan uji asumsi klasiknya ..terima kasih bantuan pencerahannya om
Assalamualaikum pak. Saya mau bertanya, apakah dalam regresi berganda semua variabel independen boleh variabel dummy? Misalkan ada 3 variabel independen ketiganya dummy, dan bagaimana cara membaca hasil regresi pada variabel dummy di spss?
sebaiknya hindari dummy yang berlebihan. karna pada dasarnya regresi adalkah alat untuk data yang rasio. terima kasih
Om saya sedang melakukan olah data penelitian utk tesis saya menggunakan regresi linier sederhana dengan variabel independen berupa var dummy… apakah utk regresi macam ini tetap hrs memenuhi uji prasyarat uji asumsi klasik juga seperti regresi linier lainnya? mohon pencerahannya krn saya pernah coba uji normalitas yang variabel dummy tidak ada hasilnya ..makasih sebelumnya
Jawabannya tidak harus mas. Karena karakteristik dummy itu memang berbeda dari rasio seperti yang diharapkan data regresi pada umumnya. Terima kasih
Pertanyaan lanjutan saya adakah buku referensi yang bisa saya gunakan sebagai rujukan untuk melakukan regresi linier sederhana dengan salah satu variabel dummy dan uji asumsi klasiknya ..terima kasih bantuan pencerahannya om
klo buku mungkin akan sulit diperoleh. karena buku membahas hal yang ideal. saya sarankan cari artikel jurnal tentang dummy dan regresi sederhana. secara tersurat mungkin tidak tertulis, tapi perhatikan langkah yang dilakukannya. terima kasih
Assalamualaikum.. Pak. Saya mau tnya.. Saya mahasiswi semester akhir..
Penelitian saya ttg pengaruh pembiayaan terhadap perkembangan UMKM..
Variabel X saya ratio dan Y menggunakan dummy.. Analisis yg saya gunakan kira kira apa ya??
https://youtu.be/hHfQaOGsm9o
Sudah saya jelaskan divideo ini ya..
Pak izin bertanya, terkait penggunaan Ln dan Log10 dalam spss itu digunakan untuk kondisi seperti apa yah?
https://youtu.be/hHfQaOGsm9o
Sudah saya jelaskan divideo ini ya..
Assalamualaikum pak, saya sedang menyelesaikan penelitian tentang pngruh rasio keuangan terhadap financial distress, dimana Financial distress memakai variabel dummy. Nah kata dosen saya bagaimana menyatukan variabel rasio keuangan yg berupa persentase dan variabel dummy yg memakai angka seperti 0,1,2 ? Kan itu berbeda ? Apa bisa variabel x yg berupa rasio” disatukan dg variabel y yaitu variabel dummy ?
iya .. bisa, variabel independen bisa ratio.
Assalamualaikum.. Pak saya mau tnya..
Saya sedang melakukan penelitian pengaruh pembiayaan terhadap perkembangan umkm.. Kata dosen saya yg variabel Y menggunakan variabel Dummy dan X dalam bentuk ratio.. Sebaiknya saya menggunakan analisis nya bagaimana ya pak?
https://youtu.be/hHfQaOGsm9o
Sudah saya jelaskan divideo ini ya..
Selamat sore pak, saya mau bertanya.. variabel x saya ada 3, salah satunya menggunakan dummy. Tetapi variabel Y saya tidak dummy.. Sementara dosen saya menyuruh saya menggunakan logistik. Apakah bisa pak? Terimakasih..
bisa. jawaban lebih detil silahkan melihat video TJBudi#02. terima kasih
Selamat siang pak, saya Harti, Mahasiswi Pertanian Agribisnis. Saat ini saya sedang melakukan revisi penelitian, karena sebelumnya penelitian skripsi saya menggunakan analisis regresi berganda. Di sini ada permasahan dari mulanya diketahui bahawa X1 Harga X2 biaya Produksi dan Y Volume penjualan. Jadi, permasalahannya adalah di X1 Harga ini sebenarnya ada 2 Harga yaitu nilai 13.000rb dan 25.000rb per bulan. Otimatis harga ini berpengaruh terhadap Y Volume penjualan. Disebelumnya saya hanya menggukanan 1Harga di X1. Kemudian Dosen saya menyarankan menggunakan Analisis Dummy sedangkan saya belum menguasainya caranya bagaimana yaa pak. Untuk menjawab permasalahan saya di atas.
maaf pak agung saya mau bertanya,
variabel y saya berskala likert dengan rentang 1= sangat tidak setuju – 5= sangat setuju. variabel y saya ini memiliki beberapa item.
yang ingin saya tanyakan,
1. apakah saya harus merubah variabel y saya menjadi variabel dummy atau
2. saya input saja hasil total item saya ke spss? apakah itu bisa langsung dicari regresi logistik binernya pak agung?
mohon arahannya pak, terimakasih sebelumnya..
jika ingin menggunakan regresi biner, tentu harus dikonversi menjadi dummy.. terima kasih
Selamat pagi pak Agung,
Pada suatu tulisan disebutkan simbol Y= f (X, Z, I) pada regresi berganda. selanjutnya simbol Z dan I diambil dari mana?
Kata kuncinya ada di regresi berganda, dimana fungsinya memang lebih dari satu variabel independen. Jadi mungkin saja itu hanya simbol untuk x2 dan x3.
Pak Agung mohon bantuannya, saya mahasiswa tingkat akhir, sedang melakukan uji regresi berganda dengan Y skala interval (frekuensi interaksi hasilnya Y bervariasi dari 0 s/d 8), dan X1,X2,dan X3 skala interval, namun X4 dan X5 menggunakan Dummy.
Hasil Residual tidak normal saat diuji, jadi dicoba ditransformasi ke bentuk lnX, karena Y terdapat data nilai nol yang tidak dapat menggunakan lnY pada spss, dosen juga tidak sependapat dengan ln y+1 karena tidak ada rujukan kuatnya.
Apakah benar untuk variabel independent (X) yang menggunakan dummy 0-1 berarti tidak di ln kan? karena memang tidak ada nilai dari ln nol.. Kemudian yang di ln hanya X yang berskala interval saja?
Mohon koreksinya jika saya salah, terima kasih.
memang benar nilai 0 tidak bisa di-LN kan. itulah sebabnya saya selalu merekomendasikan menggunakan variabel skala rasio karena regresi menganut linearitas. mungkin bisa dicoba dengan cara eliminasi data pencilan sehingga residual terdistribusi normal. terima kasih
selamat malam pka, ijin bertanya. apakah penentuan kategori referensi pada variabel dummy berpengaruh terhadap signifikansi variabel lain? kalau iya, kenapa pak? terima kasih
tidak ada pengaruh. hanya nanti ada perbedaan pengartian nilai negatif atau positif di koefisiennya saja. terima kasih
Selamat malam pak izin bertanya ,variabel x saya ada 2 var dummy dan 2 var dengan skala likert terus var y nya likert juga .1. apakah data tersebut bisa diolah secara bersama” misal dengan regresi berganda. 2 apakah bisa data tersebut di uji hipotesis dengan uji t dan f .note ,maaf pa cuman mau memastikan terimakasih banyak .
sepertinya pertanyaannya sama dengan yang sebelumnya ya.. sudah dijawab. terima kasih.
Selamat malam pak ,izin bertanya . Klo salah satu variabel x saya dummy terus sisanya skala likert dan variabel y saya likert juga ,”apakah data tersebut bisa dilakukan uji-f” ? Terimakasih
ada beberapa yang membuat tutorial tentang regresi ordinal. di SPSS pun ada menu tentang ordinal regression. hanya saya secara pribadi belum pernah mencoba dan menyarankan. saya ada dipemahaman jika regresi itu harus ada variabel skala rasio baik disalah satu Y maupun X nya. karena regresi menganut linearitas. mungkin lain kali saya akan coba pahami apa itu ordinal regresi.
Selamat sore pak, izin bertanya..
skripsi saya ada 4 variabel independen dimana X1, X2, X3 skala rasio dan X4 skala ordinal (pemberian tingkatan/RANKING 1 – 5), Y nya rasio. disarankan dosen saya menggunakan Regresi Berganda, tetapi bagaimana dengan data X4 saya yg skala ordinal tersebut ya pak? apakah harus di manipulasi data dengan MSI terlebih dahulu transformasi ordinal ke interval atau bagaimana ya pak? mohon pencerahannya pak, Terimakasih sebelumnya..
Selamat malam. Paling mudah adalah membuatnya menjadi dummy mbk. Misal nilai 1 sampai 2 dikonversi menjadi 0, kemudian 3 sampai 4 dikonversi menjadi 1. Terima kasih.
pak saya mau bertanya, saya punya 3 variabel independen, 1 variabel moderasi, dan 1 variabel independen.
salah satu variabel independennya adalah menggunakan dummy,
ketika saya lakukan uji normalitas, hasilnya data tidak normal.
saya sudah mencoba transformasi data dengan menggunaka sqrt dan log10 hasilnya tidak normal
(dan data ada yang hilang)
kemudian dari data yg sudah ditransform, karena masih belum normal saya lakukan outlier dan hasilnya normal..
sedangkan kalau dari awal daya langsung menggunakan outlier tanpa ditransform datanya tidak normal.
apakah boleh menggabungkan transform dan outlier sekaligus?
terimakasih
boleh. tapi perlu diperhatikan apakah hasil akhir operasi tersebut masih bisa mewakili data lapangan sesuai metode yang digunakan ya… titik pentingnya ada disitu. terima kasih
Hallo pak saya mau bertanya jika x1, x2, dam x3 saya semuanya pakai rumus perhitungan sedangkan variabel Y saya pakai dumy… itu pakai uji apa ya pak yg cocok?
mungkin regresi logistik lebih tepat ya… terima kasih
Pak bisa jelaskan mengenai variabel dummy kategori -1? Terimakasih.
Dummy itu sebenarnya skala nominal mas. Skala nominal itu hanya menyatakan simbol saja, tidak ada hubungan dengan nilai yang terkandung di variabel tsb. Kebetulan biasanya dummy itu antara ya dan tidak. Ya biasanya identik 1, 0 biasanya identik tidak. Keduanya bukan berarti ada yang lebih tinggi posisinya. Sama seperti dua kelompok, satu kelompok laki laki, satu kelompok perempuan. Keduanya sama.
Begitupun tanda -1. Artinya 0 dan -1. Terima kasih
Selamat Sore, Pak Agung.
Saya ingin bertanya, sebelumnya untuk judul penelitian saya “pengaruh implementasi PSAK 72 terhadap kinerja keuangan perusahaan real estate”. Disini variabel independennya adalah PSAK 72 dan variabel dependennya adalah kinerja keuangan (rasio likuiditas, aktivitas, solvabilitas, profitabilitas dan pasar).
Variabel independennya yaitu variabel dummy (yg belum menerapkan= 0; yg sudah menerapkan= 1) dan semua variabel dependennya skala rasio.
Jadi apakah benar saya menghitungnya satu-persatu dengan menggunakan regresi berganda SPSS?
Karena mengingat bahwa berarti model penelitian saya berarti ada lima. Ex: Y1= a + b1x1 ; Y2= a + b2x2 ; dst
Terimakasih sebelumnya.
jadi satu variabel independen untuk 5 variabel dependen? rasanya agak aneh ya…lebih baik kelima variabel dependen itu dijadikan suatu indeks kinerja keuangan terlebih dahulu. bisa skornya 1 sampai 100, atau menggunakan luas area jaring jaring dengan 5 koordinat misalnya. baru nanti menggunakan regresinya satu model saja. terima kasih
Selamat siang pak.
Saya mau tanya, saua menggunakan data panel, dgn jml perusahaan 362, dan periode waktu 9thn. Variabel y saya berbentuk rasio, variabel x1 saya juga berbentuk rasio, dan variabel x2 saya berbentuk dummy (1-0).
Yang saya mau tanyakan:
1. Untuk melakukan regresi di eviews terhadap jenis data yg sudah saya sebutkan, apakah tetap melewati pemilihan model common/fixed/random? Atau ada cara yg berbeda?
2. Dengan jumlah observasi yg saya miliki apa masih perlu melakukan uji asumsi klasik normalitas dan heteroskedastisitas?
selamat siang mas
1. iya, tetap melakukan pemilihan model common/fixed/random untuk mengetahui regresi yang akan digunakan.
2. tentu harus diuji. pengujian bukan dikarenakan banyaknya data, melainkan karakteristik data, error dan hubungan atau korelasi antara setiap variabel
terima kasih ya.. subscribe my channel jangan lupa..
Selamat malam pak, saya sedang mengerjakan skripsi dengan X sebanyak 4,1(dummy) dan menggunakan variabel moderasi. Saya sudah uji asumsi klasik dan semua data saya masukan termasuk moderasi saya jadikan variabel independent lulus semua uji normalitas, multikolinearitas, heteroskedasitisidas. Saat uji autokorelasi terdapat gejala kemudian saya lakukan uji durbin’s two step dan bisa teratasi tetapi varibel x dummy saya tidak muncul di tabel autokorelasi.
Apakah seperti itu tidak masalah? Dan bisa saya lanjutkan?
Atau saya harus hitung x dummy tersendiri? Jika iya dengan metode apa ya pak?
Terimakasih sebelumnya pak
tidak masalah mbk.. bisa dilanjutkan. terima kasih
Assalamualaikum wr.wb
Saya ingin bertanya pak. Judul penelitian saya analisis faktor faktor yang mempengaruhi rating sukuk dan hanya memakai 4 varibel x berskala rasio dan variabel y yg dummy, saya harus memakai analisis regresi apa? Dan apakh variabel x sudah ckp 4 saja. Sedangkan sampe saya hanya 30 lebih apakah bisa?
wa alaikum salam.. dalam menentukan alat analisis yang digunakan terlibih dahulu deskripsikan skala masing masing variabelnya ya.. bukan nama variabelnya (variabel dependen atau Y). saya sendri sampai sekarang tidak paham sukuk itu apa.. terima kasih
Selamat malam pak, saya ingin bertanya judul penelitian saya yaitu “Analisis ekonomi global terhadap neraca pembayaran”, variabel nya ada pdb, inflasi, nilai tukar, ekspor impor, dan neraca pembayaran variabel terikat, dan saya ingin membandingakan perkembangan ekonomi global setelah krisis dan sebelum krisis yang berpengaruh terhadap neraca pembayaran.
Sebaiknya saya menggunakan metode penelitian apa ya pak, dan variabel dummy saya yang mana ya pak?
terimakasih pak
Selamat malam pak saya mau bertanya, saya mahasiswa tingkat akhir, variabel X saya hanya 1 dan itu variabel dummy. Tapi variabel Y saya bukan dummy dan saya juga menggunakan variabel intervening. Apakah bisa menggunakan path analysis yaa pak? Apakah nanti akan mempengaruhi pada uji asumsi klasik saya juga? Misalkan data tidak normal/terjadi heterokedastik dsb. Terimakasih pak
Bisa…justru penjelasan tsb merupakan ciri ciri path analysis
Selamat malam pak, saya mahasiswa tingkat akhir ingin bertanya apakah boleh dalam skripsi jika salah satu variabel x saya menggunakan dummy (1 dan 0) lalu variabel y saya juga menggunakan dummy?
Selamat malam mbk.. klo variabel independennya (variabel x) hanya satu dan itupun dummy, saya tidak rekomendasikan.
Lebiha baik pakai korelasi dan menurut saya itu belum layak diangkat skripsi ya… Soalnya nanti pembahasannya terlalu singkat.
Solusinya? Baiknya variabel x nya ditambah beberapa variabel yang berskala rasio. Kemudian gunakan regresi logistik jika variabel y nya dummy.
Variabel x saya ada 4 nah di salah satu variabel x saya menggunakan variabel dummy, y saya juga dummy pak. Apa bisa menggunakan regresi logistik jika seperti itu pak?
Pagi pak ,variabel dependent (y) saya bersifat skala apakah bisa di tarnformasikan ke dummy pak dan kalau bisa bagaiman caranya pak
saya berikan contoh ya.. misal variabel pendapatan (skala rasio) untuk mengkonversi menjadi dummy, misalnya akan saya bagi ke dua kelompok. kelompok yang nilainya 1 adalah kelompok yang pendapatan besar, kelompok yang nilainya 0 adalah kelompok yang bernilai kecil.
misal x = nilai maksimal pendapatan dari responden
y = nilai minimal sebaran pendapatan responden
z = batas antara kelompok 1 dan 0, bisa nilai tengah, rata-rata, dll
maka kelompok 1 adalah orang yang memiliki pendapatan dari z ke x.
dan kelompok 0 adalah orang yang memiliki pendapatan dari y ke (z-1).
nilai z bisa dijabarkan sesuai hipotesis penelitian atau teori tentang pendapatan. terima kasih
selamat sore pak, saya ingin bertanya. saya menggunakan aplikasi eviews dan
variabel X1 ( rumus ), X2 (dummy), Y (Dummy) , Moderasi ( Rumus) dan saya menggunakan regresi logistik. pertanyaan saya
1. apa benar saya menggunakan regresi logistik?
2. pada saat pengolahan data untuk x1 dan y bisa menggunakan metode binary, sedangkan untuk mengolah data x2 dan y tidak bisa menggunakan binary tetapi bisa menggunakan LS. itu bagaimana ya pak? apa saya menggunakan LS juga untuk mengolah data x1nya ?
terimakasih pak sebelumnya
1. Menggunakan regresi logistik
2. Bagaimana jika langsung running x1 dan x2 untuk Y menggunakan binary?
Selamat siang pak Agung, saya ingin bertanya mengenai cara olah data saya jika variabel dependen dan moderasi saya menggunakan dummy, apakah variabel moderasi tersebut tetap dikalikan dengan variabel independentnya? atau cara pengolahannya bagaimana ya pak? terimakasih
Berita buruknya dummy sepertinya kurang kuat jika digunakan variabel moderasi, hal ini terkait nilai 0 dan 1. Nilai 0 akan menghilangkan variabel pengali atau independen yang lain. Solusi? Ubah dummy menjadi skala ordinal minimal. Terima kasih
selamat siang pak, saya ingin bertanya. apakah jumlah sampel variabel dummy antara yg bernilai 0 dan yg bernilai 1 jumlahnya harus sama atau seimbang? jika tidak, adakah prosentase yang harus digunakan? mohin jawabannya pak, terimakasih
Iya..ada. usahakan berimbang. Maksimal 60-40 lah.. saya pernah mencoba data tidak seimbang, hasilnya tidak baik dan tidak signifikan.
apakah ada teori yang menyatakan dummy harus seimbang pak? saya sudah mencari tetapi belum menemukan. saya sedang mengerjakan skripsi dan alasan saya menentukan tahun penelitian tersebut agar dummy yg saya gunakan datanya seimbang.
hmm… saya memang belum menemukan teori harus seimbang. ini berdasarkan pengalaman saja. jika datanya tidak seimbang, maka bagaimana regresi akan memformulasikan model yang tepat? apalagi ini berbicara peluang. istilahnya sebaran datanya kurang banyak sehingga nanti mempengaruhi tingkat kepercayaan. terima kasih
Mas, mau nanya kalau x1, x2 menggunakan dummy dan y menggunakan rumus, apa bisa di uji asumsi klasik?
Mbk…pertanyaan ini pernah ditanyakan. Scroll dulu ke bawah ya…terima kasih
Malam Pak agung, bagaimana ya contoh model regresi dengan Menggunakan 2 dummy variable Dan peran masing2 parameternya? mohon bantuannya Pak🙏
Sebenarnya tidak jauh berbeda dengan satu dummy variabel. Karna penjelasannya saat uji T akan dilakukan secara parsial. Jika ada kesempatan nanti saya berikan contoh di artikel terpisah. Terima kasih
Selamat malam bapak, saya mahasiswa semester akhir sedang menyusun skripsi, disini jumlah sampel saya ada 44 dengan 7 variabel independen dan dependen dummy, awal saya menggunakan regresi logistik menggunaoan aplikasi spss tidak ada muncul warnings, sekarang selalu muncu denga tulisan warning “estimation failed due to numerical problem. Possible reason are: (1) At least one of the covergence criteria LCON, BCON is zero or to small or (2) the value of EPS is to small (if not specified, the default value that is used may be to small for this data set)) ini kenapa ya pak bisa begini ? Sudah saya coba tambah jumlah sampel dll masih muncul seperti itu.
coba cek data datanya mbk. kuatirnya ada data yang bukan numeric. misalnya keinput koma atau text. terima kasih
pak saya mau tanya,
variabel X1 (rumus)
X2 (dummy)
Y(Dummy)
1. saya pakai SPSS, bisa pakai regresi logistik pak?
2. apakah ada tutorial untuk regresi logistiknya pak?
pak, untuk measurenya di SPPS harus diubah jadi nominal ga ya utk dummy nya?
iyes..harus diubah karna itu prosedur standar ya… terima kasih
ada mbk.. di blog ini coba ketik kata kunci regresi logistik mbk. kebetulan dulu skripsi saya juga menggunakan regresi logistik. terima kasih
selamat siang pak agung saya ingin bertanya pak karena skripsi saya berhubungan dengan variabel dummy yang berada pada variabel Y , kalau mau melakukan uji analisis logistik itu apa saja ya pak yang di regres ?, contoh nya kalau di regresi linear berganda kan uji asumsi klasik, analisis regresi linear berganda, uji t uji f dan koefisien determinasi yang diperlukan , nah kalau di dalam analisis logistik itu apa saja ya pak ? judul dari skripsi saya yaitu pengaruh likuiditas, laverage dan profitabailitas terhadap financial distress pak, mohon jawabannya ya pak
saya membaca buku regresi berganda dan regresi logistik. tidak ada uji asumsi klasik pada regresi logistik mbak.
pak saya cahya mau bertanya jika variabelnya tidak ada indikator tapi hanya skla dummy hanya bisa diuji lewat uji regresi berganda, uji asumsi klasik dan uji hipotesis kecuali uji validitas dan reliablilitas apakah bisa pak???
sepertinya tidak ada yang bisa diuji jika dummy semua.
Pak saya mahasiswa semester akhir yang sedang mengerjakan skripsi dengan judul pengaruh rasio likuiditas, leverage, profitabilitas, kepemilikan manajerial, kepemilikan institusional, dewan direksi dan dewan komisaris terhadap financial distress. Saya sudah punya data terkait variabel diatas, dan variabel y merupakan variabel dummy. Disini saya menggunakan regresi logistik. Pertanyaan saya :
1. Apakah saat ingin menginput data langsung menggunakan data hasil nilai rasio yg saya kerjakan tanpa mengubahnya ?
2. Apakah jumlah 36 sampel cukup dan normal ?
3. Apakah bisa sebagian variabel x saya yaitu x4 x5 x6 x7 menjadi variabel dummy ? Dan bagaimana aturan menganalisis dan menginputnya dalam spss ?
Mohon bantuannya pak.
pertama, data diinput sesuai keadaannya terlebih dahulu atau disebut data mentah. bisa melakukan konversi data jika ternyata data tidak signifikan (baca di blog ini artikel tentang “tehnik setrika data”. kedua, tergantung populasinya, baca artikel di blog ini tentang “minimal data regresi”. ketiga, analisis ini menggunakan regresi logistik. saya sudah membahasnya di artikel “semua tentang regresi logistik”. input dalam spssnya adalah saat memberikan scale di deskripsi variabel, diberi keterangan categoric, saya belum menjelaskan ini. semoga ada waktu untuk membahas spss. aturan menganalisisnya sama dengan dummy di regresi umumnya. hanya saja pada regresi logistik “variabel yang memiliki nilai x = 1, akan memiliki peluang sebesar odds ratio kali dari variabel yang memiliki nilai x = 0”.
terima kasih
mbak miftah apakah sudah menemukan hasilnya ? sepertinya judul kita hampir sama mbak ..
judl saya pengaruh intellectual capital dan enterprise risk management terhadap kinerja keuangan pada perusahaan farmasi” yang saya bingungkan variabel x yang ke dua pak saonya itu menggunakan metode dummy.
maaf, pertanyaannya belum jelas mas.. saya baca berulang belum juga paham. sebaiknya mas pahami dulu regresi berganda. terima kasih
pak saya mau nanya, saya masih bingung pak cara mengolah metode dummy ini pak, jadi judul saya itu terdiri dari 2 variabel x dan salah satu di variabel x ada menggunakan metode dummy ini pak, maka saya menggunakan uji apa aja ya pak dan untuk mengolah laporan keuangan k metode dummy lewat spss itu gimana ya pak? mohon bantuannya bapak
Assalamu’alaikum
pak judul skripsi saya kan “Pengaruh pembelajaran zoom meeting terhadap hasil belajar matematika” menurut bapak, saya menggunakan regresi logistik atau dummy variabel pak?
Jika variabel Y nya adalah nilai matematika, artinya variabel tersebut berskala rasio. Jadi bukan regresi logistik yang digunakan. Bisa regresi berganda. Terima kasih
jika saya ingin menggunakan dummy variabel bisa tidak pak?
Assalamualaikum pak, saya Diffa
Saya mau nanya
Salah satu variabel x1 saya ada yg dummy, jujur saya bingung untuk variabel dummy, uji apa saja yg harus dilakuin ? Apakah harus uji validitas reliabilitas ? Maka dari itu saya nanya uji apa saja yg dilakuin di variabel dummy, mohon jawabannya ya pak
Ada beberapa uji yang dilakukan bukan pervariabel, melainkan uji sekaligus. Silahkan baca uji asumsi klasik part 1 dan 2 di blog ini. Untuk uji validitas dan relibilitas tentu dipakai karna itu menguji kuesioner.
Wah jadi dummy variabel ttp dilakukan uji validitas sma reliabilitas ya ? Ada tutorialnya kah untuk uji validitas sama reliabilitas pda dumy variabel ,terimakasih banyak
assalamualaikum pa agung
saya mau tanya, judul peneltian saya “Media, slack, dan profitabilitas terhadap CSR”
dimana
X1 : variabel dummy
X2 : rasio
X3 : rasio
Y : rasio
ketika uji asumsi klasik
untuk uji norma, hetero,multi hasilnya norma pa tetapi untuk uji auto tidak normal
lalu saya menggunakan metode Cochrane orcutt dan kemudian uji auto saya normal
kemudian saya melakukan uji t dan f dengan data sebelum tranfrom ( Cochrane orcutt )
semua X saya tidak berpengaruhi terhdap Y pa
lalu saya coba lagi uji t dan f menggunakan data sesudah tranfrom dan salah satu X saya ada yang berpengaruh dengan Y
yang mau saya tanyakan apakah saya boleh menggunakan data yang sudah ditranform itu pa untuk di lampirkan di skripsi atau bagaimana pa ?
terima kasih pa Agung
Wa alaikum salam. Justru data transform itulah yang sekarang menjadi data penelitian. Tentunya bisa dilampirkan dan dibahas di skripsi namun tetap mengacu kepada data aslinya. Baca di https://www.google.com/amp/s/agungbudisantoso.com/tehnik-setrika-data-pada-regresi/
Terima kasih
Selamat sore mas, boleh nanya
X1 rasio, X2 rasio, X3 Dummy dan Y rasio
Yang saya mau tanyakan
1. Apakah ini di lakukan uji asumsi klasik (semua X) ?
Terima kasih
maaf mau bertanya, jika ada 1 independen dan 1 moderasi, namun hasil justru menunjukkan satu variabel tersebut excluded (dikeluarkan), lalu bagaimana ya? apakah model regresi dapat digunakan?
Bisa…dengan syarat mematuhi hasil outputnya. Mengeluarkan salah satu variabel
Mau bertanya, jika penelitian saya ada variabel moderasi
dependen: nominal
independen: dummy
moderasi: skala (123)
jika dikalikan indpn*moderasi, hasilnya sama dgn nilai independen, terjadi multikoliniearitas, namun hasil hipotesis signifikan, apakah hasil signifikan tersebut dapat digunakan pak?
Sulit diputuskan. Karena multikol menyebabkan model menjadi tidak fit (arti fit berbeda dengan signifikan)
maaf pak saya mau tanya
saya kan pakai 5 variabel X1, X2, X4 dan Y pakai skala likert X3 pakai skala nominal/dummy .
yang saya tanyakan apakah skala dummy memakai uji validitas dan uji reliabelitas juga pak?
dan X3 yang berskala dummy itu Tipe Kepribadian , nah jika membuat tabulasi pada exel dan membuat nilai skornya itu gimana?
Mohon bantuannya ya pak
Uji validitas dan realibilitas itu menguji kuesioner. Jadi dilakukan sebelum penelitian dilakukan. Jadi perlu dan tidak memandang jenis skala variabel.
Saya ingin bertanya pak agung. Jika variabel Y saya menggunakan dummy apakah bisa menggunakan analisis regresi data panel?
bisa. data panel tapi regresi logisik ya..maksudnya selain syarat syarat data panelnya dipenuhi, tapi prosesnya regresi logistik
selamat siang pak. saya mau tanya , apabila variabel Y saya bukan dummy sedangkan variabel X saya terdapat 2 variabel dummy , lebih baik saya menggunakan uji regresi berganda atau uji logistik ya pak? terus apakah variabel dummy berpengaruh terhadap normalitas data? soalnya data saya masih tidak normal. mohon pencerahannya ya pak . terima kasih
regresi berganda. dummy pengaruh terhadap normalitas. iya. usahakan jumlah dummy nya balance
Maksudnya balance disini jumlah nya sama pak? Kalo saya pake transformasi data untuk variabel dummy nya bisa tidak ya pak?
Sore Pak,
Jika variabel Y saya menggunakan Dummy, lalu X1, X2, X3 saya menggunakan skala rasio, itu analisis regresinya pakai apa yaa? regresi berganda atau logistik ?
Regresi logistik
kalau pakai regresi berganda tidak bisa ya pak ? harus logistik kah?
Selamat malam pak, mau bertanya. saya sedang melakukan penelitian tentang “analisis willingness to pay terhadap premi asuransi pertanian”. saya menggunakan variabel independen dummy (ya dan tidak) dan variabel dependen sebanyak 7 variabel, yaitu usia, pendidikan, pendapatan, lama usaha tani, luas lahan, pengalaman risiko dan status kepemilikan lahan. 3 dari 7 variabel (pendidikan, risiko dan status lahan) merupakan variabel dummy. apakah variabel tersebut dapat dilakukan uji normalitas? terima kasih
pada prinsipnya yang diuji dalam uji normalitas adalah galatnya atau errornya. jadi tidak berpengaruh terhadap jenis variabel independennya. jadi jawabannya bisa. terima kasih
Selamat siang Pak Agung, apabila saya melakukan penelitian dengan variabel X Pelatihan (Dummy) variabel Z Kepuasan Kerja (Interverning) dan variabel Y kinerja tempat kerja (Y). saya menggunakan regresi untuk melihat pengaruhnya. apakah sudah benar? untuk melihat pengaruh variabel interverning lebih baik menggunakan path analysis atau uji sobel pak?
terimakasih
Selamat siang mbk…menurut saya kepuasan kerja tidak hanya dipengaruhi faktor pelatihan ya mbak.. jadi mestinya masih bisa dieksplore lagi variabel yang diambil. Untuk intervening, banyak yang menggunakan regresi ataupun path. Saya tidak bisa menentukan mana yang lebih baik karena dua duanya merupakan alat analisis.
Selamat sore bapak Agung, terimakasih untuk responnya. untuk x dengan variabel dummy bolehkah menggunakan path analysis bapak?
terima kasih pak kontennya
saya masih bingung, variabel dummy (independen) walaupun skala nominal tetap boleh menggunakan regresi linier berganda pak? walaupun bukan interval atau rasio
tanpa perlakuan khusus terlebih dahulu?
terima kasih pak
Boleh digunakan tetapi jumlah variabel indeoenden hendaknya mayoritas tetap rasio. Perlakuan khusus sebenarnya dalam software tetap dilakukan terbukti dalam deskripsi skala di spss sudah dibedakan. Terima kasih
selamat pagi kak .. Kak, saya mau nanya .. Saya sekarang sedang membuat skripsi. Saya menggunakan variabel kontrol yaitu jenis kelamin. Ketika menguji, jenis kelamin ini saya jadikan variabel dummy (0 perempuan, 1 laki-laki) Lalu, ketika saya melakukan uji t, didapatkan bahwa nilai ny signifikan dan nilai t serta koefisien nya positif. Lalu bagaimana cara saya menjelaskan hasil yang seperti itu kak ? Terima kasih kak
selamat siang mega. Misal 0 = perempuan, 1 = laki laki dan koeffisien +, maka laki laki memiliki nilai Y yang lebih besar dibanding perempuan.
Misal 0 = perempuan, 1 = laki laki dan koefisien -, maka laki laki memiliki nilai Y yang lebih kecil dibanding perempuan.
Terima Kasih
Salam pak, ijin bertanya.. instrument penelitian saya kuesioner dengan skala guttman (pilhan Ya dan Tidak / 0 dan 1), semua variable X1, X2, dan Y menggunakan kuesioner skala guttman. Analisis statistic yang cocok saya gunakan untuk menguji pengaruh variable independen ke variable dependen apa ya? apakah dengan analisis path di spss bias?
Variabel dummy kan satu variabel 1 pertanyaan, kalua saya satu variabel ada yang 4 pertnyaan, 18 ertanyaan, dan 20 pertanyaan. apa itu bias disebut dummy?
Kendala saya saat melkukan analisis regresi linier semua variabel tidak berpengaruh baik menggunakan logistic juga, sya input data ke spssnya rata2 total skor variabel sehingga yang di input angka 0 atau 1, menggunakan total skor tanpa dirat2kan juga sudah tpi tetap hasilnya tdak berpengaruh R square nya juga sangat kecil skali.
Jika semua variabel skala guttman, sebaiknya mas menggunakan analisis nonparametrik. Kurang tepat jika memaksa menggunakan regresi. Terima kasih
Terimakasih pak sudah dijawab. Kalau menggunakan analisis noparametrik apa kita tetap bsa mengeetahui pengaruh antar variabel bebas dengan variabel terikat? Atau hanya sebatas analisus deskriptip sja?
Tetap bisa menjadi analisis inferensia, namun bukan membicarakan pengaruh. Tetapi membahas tentang korelasi atau hubungan antar variabel.
Sore pak, mau bertanya. kalau misalkan variabel x1 (interval), x2 (interval), x3 (dummy (ya/tidak))… jika variabel Y nya menggunakan dummy (ya/tidak) juga, apakah bisa? kalau bisa analisis apa yang digunakan?
selamat malam … pakai regresi logistik ya.. terima kasih
Halo kak, mau nanya, penelitian saya menggunakan variabel dependen ttg Cumulative Abnormal Return dan variabel independen x1: dummy variabel peluang investasi tinggi vs rendah, dan variabel kontrol berupa data biasa x2: size, x3:ROA, x4: DER, apakah uji dengan menggunakan data dummy ini harus memenuhi uji asumsi klasik?
jika mayoritas dummy, apa yang akan diuji dengan uji asumsi klasik?
Permisi ka, mau tanya saya sedang melakukan penelitian terus data variabel independen dan dependen nya ituu berupa dummy variables. Apakah bisa dilakukan uji logistic apa harus ada tambahan variabel dependen berupa rasio. Terimakasih ka
Baiknya ditambah dulu variabel independen dalam skala rasio ya… Klo dummy vs dummy itu analisisnya cukup korelasi nonparametrik.
Permisi bapak, saya ingin bertanya terkait variabel dummy. Jadi penelitian saya ini Y dan X3 dlm bentuk variabel dummy, sedangkan X1 x2 dan X4 dlm bentuk rasio semua. Kemudian saya uji regresi data panel dg eviews dan nilai R square dan adjusted itu 1.000, padahal data lain itu sudah sesuai dan bisa dinterpretasikan. Jika seperti ini, untuk uji koefisien determinasi interpretasinya bagaimana? Apakah hasil tersebut disebabkan karena variabel dummy pada dependen Y? Apakah bisa tetap di regresi berganda sata panel? Terima kasih
Ini sudah didiskusikan lewat wa. Terima kasih
Permisi pak. Saya mau tanya sebenernya untuk apa sih interaksi dummy variabel itu?
Klo bicara untuk apa, bisa digunakan untuk mengakomodasi variabel yang berskala nominal. Dalam rancob bisa digunakan mendeskripsikan perlakuan meski tidak umum.
Tapi yang jelas, dalam regresi dia mengakomodir variabrl berskala nominal. Karna terkadang ada variabel yang tidak bisa dipaksa interval atau rasio. Terima kasih
Jadi apabila saat pengujian hipotesis yang dipakai berpengaruh atau tidaknya tanv dilihat variabel aslinya atau kah variabel interaksinya pak.?
Bisa juga begitu..karna pada umumnya dummy hanya dilihat dari signifikan pengaruh atau tidak. Terlalu jauh jika menggunakannya sebagai model yang utuh
Jika mau melihat adanya interaksi atau tidak maka variabel interaksinya yang dilihat.
Halo Pa, saya sedang menguji pengaruh hari perdagangan terhadap return saham LQ45. Variabel independennya adalah hari perdagangan dijadikan dummy, dan return saham sebagai variabel dependen.
Ketika saya masukan uji regresi, salah satu hari perdagangan menjadi excluded variabel. apakah itu tidak apa-apa pa?
halo aulya. ini maksudnya variabel tersebut tidak dimasukkan kedalam model atau istilahnya tereliminasi. bisa disebabkan karena menggunakan metode backward atau forward pada SPSS. mengenai bermasalah atau tidak, tergantung dari posisi variabel tersebut. jika memang variabel tersebut menjadi variabel vital dalam penelitian, maka menjadi masalah karena seharusnya variabel itu ada di persamaan. sebaliknya, jika bukan variabel pokok pembahasan, maka tidak mengapa variabel tersebut tereliminasi. terima kasih
Maaf pak mau tanya saya sedang skripsi dan variabel Y, X2 saya dummy lalu untuk X3 nya itu pake altman z-score dengan skala rasio apa X3 ini pake dummy juga ?
yup.. altman z-score nantinya akan menghasilkan sebuah index. karena dummy hanya ada 2 kategori, yakni 0 dan 1, maka nantinya dummynya jadi banyak. ini perlu penjabaran khusus. jika index nanti menghasilkan 3 kategori, maka jumlah dummynya nanti juga ada 3.
assalamualaikum pak, mau bertanya
salah satu variabel independen saya adalah dummy (1,0), sedangkan variabel yang lain rasio. saat uji hetero dengan glejser, ternyata terjadi hetero hanya pada variabel dummy nya.
bagaimana solusinya pak.
Wa alaikum salam mbk sara. Sepamahaman saya uji glejser itu bersama sama runningnya variabel variabel x terhadap nilai mutlak errornya.. kok bisa mbk menyimpulkan hanya dummy saja ya..?
Tapi okelah…asumsikan mbk benar. Maka cara yang efektif menghilangkan masalah hetero adalah menambah variabel yang sekiranya bisa berpengaruh kuat terhadap Y. Terima kasih
Oh iya…sebelum tambah variabel atau data, bisa juga dilakukan transformasi data mbk. Saya kira tadi sudah ditransformasi datanya
Maaf pak saya mau bertanya. Saya skrg sedang melakukan penelitian dengan varibel Y (rasio) dan 2 variabel X (rasio) dan 1 variabel X (dummy). Saat melakukan uji heteroskedastisitas, utk variabel X rasio hasil uji nya oke, tp utk variabel X dummy hasilnya tidak oke (nilai sig nya 0,000). Kira2 hrs bagaimana ya pak?
Sudah menggunakan uji glejser belum mbak? Setau saya uji glejser digunakannya serempak (semua variabel independen dimasukkan) tidak satu persatu.
Sudah pak, saya sudah menggunakan uji glejser
maaf pak sblmnya, saya saat ini sedang dalam proses skripsi, y saya Ketepatan Waktu Pelaporan Keuangan (dummy) dg 6 x yaitu profitabilitas, Leverage, ukuran perusahaan, kualitas Kap (dummy), opini audit (dummy) , dan likuiditas. nah dsini saya mau tnya beberapa hal pak:
1) karena mengetahui y saya adalah dummy, saya memilih memakai regresi logistik, sehingga apakah benar jika memakai reg. logistik itu tidak perlu uji asumsi klasik, dan langsung uji t, f, dan r kuadrat?
2) bentuk persamaan regresi logistik itu apa beda dengan persamaan dlm regresi linier? bentuk nya langsung Y=… atau Y nya dalam bentuk lain sperti per per gitu?
Iya mbk yona… saya maafkan.
Sebaiknya mbak baca artikel di blog ini yang berjudul “semua tentang regresi logistik” dulu deh..
Semoga mencerahkan..terima kasih
Selamat sore, pak saya mohon jawabannya.
Saya melakukan penelitian dengan judul X1 (dummy), X2 (Dummy), Y1 (scala likert) Y2 interverning (Nominal). Saya melakukan uji normalitas dan hasilnya tidak normal. Kira dengan variabel seperti itu apakah memerlukan uji asumsi klasik? dan jika saya menggunakan analisis jalur apakah bisa pak?
uji normalitas merupakan uji asumsi klasik yang berarti syarat untuk regresi berganda. jadi tetap digunakan. analisis jalur bisa juga jika memenuhi syarat..
Selamat siang pak, saya sedang mengerjakan skripsi saya yg berbentuk data panel dengan 5 variabel independen dan salah satunya adalah variabel dummy. Apakah regresi data panel ini bisa dilakukan dengan eviews ya pak? Karena saat menguji untuk fixed effect terdapat warning “near singular matrix” yg saya baca2 katanya itu karena ada variabel dummynya. Apakah ada solusi ya pak? karena variabel dummynya itu yg menjadi kunci di skripsi saya. Terima kasih banyak pak
Near singular matrix iti biasanya disebabkan multikolinear mbk…pastikan dulu apakah variabel tersebut py korelasi kuat tidak dengan variabel yang lain. Jika variabel dummy itu penting, maka variabel lain yang dieliminasi jika terindikasi korelasi kuat. Terima kasih
Permisi pak, mau tanya, salah satu variabel independen saya menggunakan variabel dummy, apakah setelah uji regresi berganda bisa dilanjut dengan uji korelasi parsial dengan variabel kontrol njih?
Bisa mas..
Permisi pak, saya mau menanyakan perihal uji normalitas pada variabel dummy
Variabel X saya Profitabilitas, Likuiditas dan Ukuran Perusahaan
Sedangkan variabel Y saya Ketepatan Waktu
sudah saya lakukan uji normalitas namun hasilnya data tidak normal
sudah dilakukan transform dan outlier tapi hasil masih tetap
Mohon pencerahannya
Terima Kasih.
Karna variabel independennya semua dummy, jadi agak susah karna kita tdk bisa melakukan transformasi unliniear. Satu satunya jalan untuk dummy seperti ini adalah menambah atau mengeliminasi mbk.. terima kasih
variabel independennya bukan variabel dummy pak (Profitabilitas, Likuiditas dan Ukuran Perusahaan (LnTotalAsset)
hanya variabel dependennya yang dummy (Ketepatan Waktu, Tepat Waktu=1 dan Tidak Tepat Waktu=0)
Sudah dilakukan outlier tapi belum normal pak
Mohon pencerahannya dan maaf merepotkan sebelumnya
Terima Kasih
dicoba untuk “disetrika” dulu datanya mbk. coba search artikel tehnik setrika data regresi di blog ini. bisa juga coba dianalisis parsial dulu satu persatu variabelnya, dilihat variabel mana yang layak untuk “diperhatikan lebih”. terima kasih
Selamat siang pak, mau izin bertanya.. bagaimana jika variabel independen saya merupakan variabel dummy dengan nilai 1 dan 0 ,dimana juga ada variabel moderasinya. apabila menggunakan uji interaksi maka kan harus dikalikan sehingga nanti ada nilai 0 nya.. apakah uji interaksi dengan menggunakan MRA sudah sesuai ataukah harus menggunakan teknik analisis lainnya? terimakasih
Itulah pentingnya kita harus mengenal jenis jenis variabel. Jika variabelnya berskala nominal (dalam hal ini dummy) tentu tidak bisa dilakukan pengoperasian karna nilai dalam variabel tersebut berfungsi sebagai simbol, tidak bisa dilakukan perbandingan. Sehingga jelaslah tidak bisa dilakukan moderasi.
Solusinya ubah skala variabelnya terlebih dahulu minimal ke tingkat ordinal.
selamat siang pak, saya mau bertanya terkait penelitian saya.
salah satu variabel independen yang saya gunakan adalah variabel dummy deng tipe nominal. saya mengolah dengan SPSS. pertama kali olah data tidak berdistribusi normal sehingga saya mengambil tindakan untuk mengeluarkan outlier dari data saya. lalu percobaan kedua masih tidak berdistribusi normal, lalu saya coba dengan me log kan semua variabel yang saya punya (saya tidak tahu apakah variabel dummy juga ikut di log atau tidak). lalu saat saya olah kembali di percobaan ketiga dan data berdistribusi normal namun terdapat autokorelasi, sehingga saya harus menyembuhkannya. lalu saya coba untuk olah kembali pada percobaan keempat dan sudah lolos semua asumsi klasik. namun pada percobaan keempat ini mengapa variabel dummy saya hilang ya pak di hasil/output dari olah data? jadinya hanya muncul hasil olahan untuk 3 variabel rasio, padahal saat saya melakukan uji regresi linear, saya sudah input variabel dummy yang sudah saya sembuhkan dari sakit autokol ke variabel independen.
mohon bantuannya ya pak.
mbak juvenia pratama, jika kasus begini sebaiknya mbak ikut bimbingan statistik. nanti saya lihat dulu datanya. saya tidak bisa menjelaskan tanpa menjumpai datanya langsung. terima kasih
Selamat pagi pak saya mau tanya,
Saya sedang mengerjakan skripsi tentang perbandingan dua toko
Dengan Y minat beli, X (kualitas, promosi,lokasi,brand image)
Sebelumnya saya pakai rumus linier berganda (y : a+x1b1+x2b2……+e)
Lalu disuruh dosen saya menggunakan dummy, pertanyaan nya rumus dummy yang harus saya tulis bagaimana? Karena emang sebelumnya saya nggak pernah pakai rumus dummy, terimakasih
Selamat pagi mbk… mungkin maksud dosen mbk itu adalah menggunakan regresi logistik. Sbelumnya saya tanya dahulu, nilai Y (minat atau tidak) skala variabelnya apa ya?
Akan menarik jika nilai Y nya berbentuk dummy (0 dan 1, minat atau tidak). Kemudian nantinya yang dibahas adalah peluang.
Soal rumus, silahkan lihat artikel saya tentang regresi logistik.
Terima kasih
Selamat malam pak, saya mau tanya kalau variabel indepen saya X1(rumus), X2 (dummy) , dependen (rumus/ratio) , untuk uji nya saya menggunakan apa ya ? Apa uji asumsi klasik? Atau uji logistik ? Terimakasih
selamat pagi mbk..penggunaan regresi logistik atau tidak itu tergantung dari jenis variabel dependennya. jika dilihat, variabel dependen yang mbk miliki adalah ratio. berarti menggunakan regresi berganda. uji asumsi klasik itu uji sebelum regresi dilakukan untuk mengetahui apakah data memenuhi syarat atau tidak. terima kasih
selamat malam pak, saya mau bertanya apabila skala variabel x1 (nominal), x2 (rasio0, x3 (rasio), dan variabel Y (rasio). apakah boleh menggunakan regresi logistik? pengujiannya bagaimana?
apabila memakai regresi berganda, untuk pengujian nya bagaimana?
terimakasih pak sebelumnya
analisis yang digunakan adalah regresi berganda, bukan regresi logistik. cara pengujiannya baca artikel tentang regresi di blog ini. terima kasih.
Pak mau tanya saya sedang mengerjakan skripsi tentang analisis rasio untuk prediksi financial distress untuk variabel independen saya rasio
Apakah menggunakan regresi logistik?
mbak fira sebaiknya banyak membaca lagi tentang apa itu regresi logistik.. 🙂 jika variabel dependennya berupa dummy variabel (yes/no) maka bisa menggunakan regresi logistik
Selamat pagi pak Agung,
terima kasih atas artikelnya, saya sedang skripsi dan menggunakan 4 variabel independen antara lain laba/rugi perusahaan (dummy), ukuran perusahaan (Log), opini auidt (dummy) dan konvergensi IFRS (dummy)
tetapi variabel dependent saya audit delay tidka menggunakan variabel dummy
sebaiknya saya menggunakan analisis & uji apa saja ya pak?
mohon pencerahannya..
terimakasih
selamat pagi mbk. jika variabel dependennya bukan dummy, maka analisisnya adalah regresi berganda mbak. terima kasih.
maaf pak, jadi meskipun variabel independen nya dummy bisa pakai regresi berganda ya pak..
terima kasih pencerahnnya
Bisa mbk..tapi mmg sebaiknya variabel independennya ditambah yang bukan dummy. Pengaruhnya nanti di signifikansi outputnya. Jgn jadikan dummy sbgai faktor utama di var. Independen
terima kasih pak..
Selamat sore pak, saya mau tanya klu bisa tidak klu dummy variabel di gunakan dalam model ECM.. ? Mohon penjelasannya pak.
Selamat sore mas faisal. Begitu mas tanya dummy dalam ECM kening saya langsung berkerut. Setau saya ECM kaitannya dengan data time series dan kaitannya dengan stasioner data.
Lalu bagaimana posisi dummynya?
Tapi saya pikir jgn dilihat dummy nya saja. Tergantung dari variabel independen yang lain. Silahkan baca artikel jurnal yang berjudul
Analisis makro kinerja pasar modal indonesia dengan pendekatan error correction model.saya rasa contohnya jelas disana
Terima kasih.
selamat malam pak agung, saya ingin bertanya. saya sedang mengerjakan skripsi dengan menggunakan data panel dengan metode (least square dummy variable) lsdv tetapi dummy yang saya gunakan adalah time dummy. nah pengunaan time dummy ini kegunaannya apa ya pak ? terima kasih pak.
Selamat malam mas teddy… time dummy sebenarnya sama dengan dummy dummy yang lain. Isinya 0 dan 1. Biasanya untuk menekankan apakah ada pengaruh yang berbeda antra tahun atau periode tahun tertentu dengan periode tahun yang lainnya. Misal periode tahun 1990 sampai 2000 diberi kode 1. Periode tahun lainnya diberi kode 0.
Kegunaannya seperti yang saya sebutkan tadi. Untuk mengetahui apakah ada pengaruh yg kuat atau tidak di periode tahun yang ditentukan?. Contoh kasus: trending fashion, atau teknologi, dsb.
Terima kasih..
assalamualaikum bapak punten saya mau nanya. saya sedang melakukan skripsi dan dalam judul saya terdapat variabel x (dummy) dan y (skala likert)
pertanyaan saya:
variabel saya terdpaat beberapa indikator yaitu
jenis kelamin
umur
oendapatan
pendidikan
apakah variabel x berpengaruh thd Y secara simultan.
akan tetapi saya masih rancu uji apa yg harus saya gunakan. apakah saya juga harus melakukan uji normalitas utk variabel X? terima kasih pak
mbak adinda jelaskan dulu karakteristik variabel y, karena ini juga menentukan penggunaan alat analisisnya. diatas hanya dijelaskan y skala likert tanpa tau variabel apa.
pertanyaan apakah x dan Y berpengaruh secara simultan? tentu tergantung dengan teori dan hipotesis yang digunakan. uji normalitas tentu digunakan untuk variabel yng bersifat parametrik (skala interval dan rasio).
punten bapa saya nanya lagi
jadi, penelitian saya meneliti pengaruh X terhadap Y.
dimana X (sociodemographics):
1. jenis kelamin: (laki/perempuan)
2. penghasilan: (option 1: <2jt, option 2: 2jt-5jt, option 3: 5jt-10jt, dsb)
3. usia: (option 1: 16-20th, option 2: 21-25th, option 3: 26-30th)
4. pendidikan (SD/SMP/SMA/S1/S2/S3)
sedangkan variabel Y (kegiatan online) pada kuesioner dengan option seberapa sering anda melakukan…. dengan skala pengukuran likert 1-5
1. transaksi finansial
2. penggunaan di waktu luang
3. hiburan
4. informasi
dsb.
kira2 bgm ya pak utk variabel Y nya bagaimana saya menguji validitasnya? dan utk normalitasnya? serta teknik analisis apa yg saya gunakan? terima kasih banyak ya pak saya buntu setwlah nanya kesana kemari
Maaf mbk adinda..regresi dengan macam seperti sepertinya blm ada. Regresi logistik nilai Y nya hanya 2 kategori (ya dan tidak). Tidak sampai ada 4 kategori seperti ini.
Lebih baik variabel y dikonversi dengan mengubah pertanyaan apakah anda menggunakan media online setiap harinya? Atau pertanyaan lain yg Artinya variabel y dikonversi hanya 2 kategori ya dan tidak. Klo seperti ini nanti mbk gunakan regresi logistik.
Cara lain, variabel y dimasukkan menjadi variabel x. Nanti variabel y yang sebenarnya menggunakan variabel laten. Baca artikel saya tentang perbedaan regresi, path, dan sem. Nantinya alat analisisnya menggunakan SEM.
Terima kasih
baik bapak terima kasih banyak atas penjelasannya ya pak..
Selamat malam pak, saya ingin bertanya,
Saya melakukan uji spss regresi logistik, variabel x ada 3(skala,skala,dummy), variabel y (dummy), pda saat uji multikol, hasil di tabel coefficients hanya muncul 2 variabel yg skala, variabel dummy tidak muncul, dan ada warning”for model with dependen variabel timeliness, the following variabel are constants or have missing correlation:opini. They will be delete from analysis” variabel yg tidak muncul yaitu x (opini;dummy) dan y (timeliness;dummy).
Penyebab variabel dummy tersebut tidak muncul apa ya?
ini terjadi hanya saat uji multikol ya mbak? perlu diketahui uji multikol hanya untuk variabel dependennya saja, jadi variabel Ynya tidak perlu diikutkan. karena multikol ingin melihat adanya hubungan antar variabel dependen. kemudian untuk variabel dummy, memang bisa terjadi seperti itu karena nilai variabel dummy tidak variatif (hanya 0 dan 1). untuk mengetahui apakah ada korelasi antar dummy dan variabel skala lainnya, coba gunakan analisis korelasi, spearman misalnya.
terima kasih
Pak ingin bertanya jika variabel dependennya adalah dummy apa bisa pake analisis linier berganda?
mbk gita, jika variabel dummynya pada variabel dependen, maka nama analisisnya regresi logistik. silahkan dicari artikel tentang regresi logistik ya… terima kasih..
Selamat Malam Pak,
maaf sebelumnya, artikel bapak cukup bisa dimengerti, hanya saja saya masih sedikit bingung dan ingin memastikan.
penelitian saya variabel x ada 4 dimana 3 rasio, 1 dummy, ada 1 variabel moderating (rasio), variabel Y (rasio).
berarti tdk perlu uji logistik ya Pak? karena variabel Y saya bukan dummy.
berarti saya bisa melakukan uji regresi di spss yang dimana perlakukan nya sama dengan jika smua variabel x,y,z (moderating) nya rasio?
mohon bimbingannya Pak,
terima kasih
Selamat pagi mbk… Iya, dengan kondisi seperti itu berarti mbk menggunakan regresi berganda. Terima kasih
Terima kasih Pak
Malam pak, apakah bisa jika regresi linier dengan satu variabel, dan itu hanya variabel dummy?
Selamat malam mbk. Penentuan berapa variabel independen biasanya tergantung teori yang digunakan. Jika teori atau landasannya kuat, maka tidak masalaj jika hanya satu variabel dan itu dummy. Pertanyaannya adalah apakah nanti akan valid dan memperoleh model yang baik?
Karna jika variabel yg banyak akan memiliki peluang mendapatkan r square yang baik. Baca artikel saya tentang perbedaan r square, r square adjusted, dan r square predicted.
Terima kasih
Selamat siang pak, mohon pencerahannya
Saya sedang membuat skripsi, di variabel independen menggunakan dummy. X1 2 kategori, X2 4 kategori, X3 3 katefori, x 4 3 kategori dan x5 2 kategori. Variabel Y berskala scale. Pertanyaan saya,perlu tidak melakukan uji asumsi klasik dan menginterpretasikan hasil uji regresi nya?
selamat siang mas..sebelumnya saya mau meluruskan bahwa dummy itu menggunakan kode biner (0 dan 1), jadi variabel dummy hanya ada 2 kategory, 0 dan 1. jika lebih, bukan dummy lagi, melainkan variabel dengan skala ordinal, misalnya skala likert (0 sd. 5). tapi masalahnya adalah jika ternyata variabel tersebut sebenarnya variabel nominal yang terdiri lebih dari 2 kategori. maka memang benar dibuat dummy hanya nanti variabelnya lebih dari 1. jika kategorinya ada 3, setidaknya nanti membutuhkan dua variabel dummy. ini sbenarnya akan menjadi pembahsan sendri.
jadi, perlu diluruskan lagi variabel X2 sampai x4 punya mas denny ya… sedangkan uji asumsi klasik menurut saya setidaknya mas perlu lakukan heterokedastisitas dan uji multikolinear. heterokedastisitas untuk menghindari regresi overfit, sedangkan multikolinear untuk menghindari adanya multivariabel yang menunjukkan parameter yang sama. silahkan membaca lebih detilnya lagi di uji asumsi klasik blog ini.
terimakasih,. semoga tercerahkan
oh iya..heterokedastisidas untuk dummy berbeda caranya dengan variabel skala numerik. karena dummy hanya bernilai 0 dan 1, maka biasanya yang dihitung adalah proporsi nilai 1 dan 0 dari keseluruhan. lebih baik jika keduanya balance. makin kecil proporsi salah satu nilainya, maka model sulit melakukan prediksi
Hai, pak agung. terima kasih untuk konten yang telah pak agung buat. konten ini sangat membantu. namun saya memiliki pertanyaan, bagaimana cara mengatasi variabel dummy yang menyebabkan near singular matrix pada eviews, saat mencoba model fixed effect pada regresi data panel? terlebih jika variabel dummy tersebut merupakan variabel moderasi yang digunakan untuk menguji apakah variabel dummy tersebut menguatkan atau memperlemah hasil penelitian?
permasalahannya adalah karena fixed effect juga secara otomatis akan membuat dummy, dan kemungkinan dummy yang terbentuk mirip atau mendekati pola dummy yang mas faisal tambahkan. sehingga terjadi near singular matrix tersebut. sebenarnya kemungkinan besar jika dummy-nya dihilangkan tidak terjadi demikian. namun karena dummy tersebut variabel penting, maka untuk membuktikan hipotesis bahwa dummy tersebut (yang merupakan variabel moderasi) menguatkan atau melemahkan, cukup menggunakan regresi linear berganda saja. Terima Kasih
maaf pak saya menanggapi, apakah intinya kalau kami menggunakan aplikasi eviews dan salah satu variabel independen nya menggunakan variabel dummy tidak usah melalui uji model dan langsung ke uji asumsi klasik pak ? terimakasih sebelumnya
pertama yang dilakukan uji asumsi klasik..ini sbnarnya uji pendahuluan agar syarat2 dari data yang digunakan mencukupi. berbeda uji model yang merupakan uji yang dilakukan untuk mengetahui model yang dihasilkan baik atau tidak.
Selamat pagi, pak. Saya ingin bertanya, apakah uji heteroskedastisitas dalam uji asumsi klasik regresi linier berganda harus dilakukan terhadap variabel dummy?
Heteroskedastisitas termasuk uji asumsi klasik dari regresi, termasuk variabel dummy.
Mau nanya mas. Apakah dalam variabel dummy harus dilakukan uji heteroskedastisitas?
selamat pagi pak agung, saya mau bertanya jika variabel Y (dummy) dan salah satu dari variabel X (dummy), sebaiknya saya menggunakan metode regresi apa..?
terima kasih
selamat pagi…jika variabel Y adalah dummy, berarti menggunakan regresi logistik. terima kasih
terima kasih pak untuk jawabannya…saya juga menggunakan variabel moderating dalam penelitian saya, nah jika salah satu variabel independent (dummy) dan variabel moderating (rasio) itu menghitungnya bagaimana, sedangkan yang saya ketahui apabila ada variabel moderating itu harus dikalikan antara variabel independen sama variabel moderating
terima kasih pak
Data dengan skala nominal tidak bisa dilakukan kalkulasi seperti itu mbk.. jadi variabel dummynya harus di konvert ke skala interval atau ordinal terlebih dahulu.
Bagaimana cara mengconvert.nya pak…??
misalkan variabel independen (dummy) nilainya 0 dan 1
sedangkan variabel moderatingnya misalkan (0,45 0,35 0,8)
seperti itu..
Variable moderasinya berasal dari perkalian variabel rasio dan dummy. Permasalahannya ada di dummynya.. hanya peneliti yang menangani langsung yang bisa mngkonvertnya.. krna misal begini… pertanyaan ya dan tidak dikonvert menjadi skala likert misalnya.. pertanyaan status pekerjaan dikonvert menjadi besarnya penghasilan.
Jadi variabel nominal ke ordinal atau interval lbh sulit drpada sebaliknya krna harus manual
selamat sore pak. saya mau tanya bisa tidak ya variabel kontrol dijadikan variabel independen
Selamat sore mbk nabilah..jika mendengar variabel kontrol pertama saya membayangkan adalah rancob (rancangan percobaan). Jika iya, maka konteksnya sudah berbeda, tdk bisa menggunakan regresi.
Tapi jika konteks yang lain..misalnya variabel moderasi, itu bisa saja.terima kasih
Selamat sore Pak saya ingin bertanya
jika saya menggunakan variabel dummy untuk menjadi variabel moderasi dan ternyata hasil uji asumsi klasik terjadi multikol bagaimana cara mengatasinya?
nb : variabel dummy saya menggunakan 4 kriteria
selamat sore mas.. variabel moderasi memang masalahnya ada di multikolinear. karena variabel moderasi sendiri merupakan variabel yang menguatkan ata melemahkan variabel independen. terlebih lagi jika mas menggunakan variabel interaksi, sudah pasti punya hub kuat dengan nilai X nya. sebenarnya variabel moderasi dengan data kategorik lebih tepat menggunakan SEM ketimbang regresi mas. namun jika memang harus menggunakan regresi, maka perlu diketahui variabel mana saja yang memiliki hub kuat yang selanjutnya harus dieliminasi dengan alasan kedua variabel tersebut mewakili data yang sama. terima kasih
Selamat siang Pak, terima kasih untuk jawaban sebelumnya
untuk SEM dapat digunakan aplikasi apa ya Pak? dan apakah ada artikel Bapak yang membahas seputar SEM?
Saya pernah menggunakan lisrel (nama software) untuk memproses SEM. tapi mohon maaf mas, dalam waktu dekat sepertinya saya belum membahas tentang SEM, dan saya belum menulis tentang SEM atau lisrel. mas googling dulu dan mencari di blog yang lain. terima kasih.
saya sudah menambahkan artikel tentang sem. semoga bisa membantu.
https://agungbudisantoso.com/2018/11/14/perbedaan-regresi-path-analysis-dan-structural-equation-modeling/
Assalamualaikum pak saya mau bertanyaa . Sayaa sdh mengolah variabel dummy dengan aplikasi spss. Dan pada kolom koefisien regresi dummy saya bertanda negatif . Bagaimanaa saya menginterpretasikannya pak ? Dan bagaimnaaa mengetahui selisih antara dummy tersebut??
wa alaikum salam mbk ardah. arti dari tanda negatif pada koefisien dummy yang mbk lakukan adalah bahwa logika 0 dan 1 pada dummy yang mbak munculkan ternyata berbeda dengan hasil /kenyataannya. biasanya peneliti mencantumkan tanda 1 dengan asumsi kelompok yang diberi nilai 1 lebih tinggi dari kelompok yang bernilai 0. betul begitu kan? nah, dalam kasus mbk ardah ini, terjadi kebalikannya. makanya dia negatif. selisih dummy tersbeut ya terletak pada koefisiennya. karena nilai -b pada -bx adalah saat x bernilai 1. sedangkan akan bernilai 0 saat x =0. agar lebih gampang dipahami, jika memungkinkan input vriabel x pada dummy ersebut dibalik. yang 0 jadi 1 yang 1 jadi 0, nanti pasti sudah positif koefisiennya. apakah ini akan merubah interpretasi? tentu tidak. sama saja.
selamat sore Pak. Apa benar pada regregsi logistik harus ada minimal 50 sampel penelitian? Bagaimana kalau sampelnya kurang dari 50 Pak? Padahal variabelnya adalah dummy. Pakai analisis apa ya Pak? Terima kasih.
selamat pagi mbk. regresi minimal data yang dikumpulkan adalah 30 mbk. tapi mmg lebih banyak lebih baik, jadi wajar jika sebagian menerapkan minimalnya 50. jika kurang 50 tidak masalah selagi masih diatas 30. tapi sebenarnya mengacu ke tehnik sampling ya… sesuai populasinya berapa, apakah heterogen atau homogen respondennya? itu lebih tepat menentukan berapa sample yang harus diambil. analisis ya sesuai dengan penelitian yang mbak lakukan. klo variabel independennya dummy bisa regresi berganda, klo variabel dependennya dummy pakai regresi logistik. terima kasih
asalam’alaikum Pak
Maaf pak mau bertanya, apabila variabel x nya semua dummy, variabel control nya ln (logaritma) dan variabel y nya skala, sebaiknya megunakan metode analisi apa ya dan olah data nya menggunakan spss atau eviews. hatur nuhun Pak
Wa alaikum salam..coba menggunakan regresi logistik dan gunakan spss. Jika variabel y yg dimaksud skalanya 1 dan 0
Selamat Sore pak,
Dalam Variabel dummy, apakah ada dasar penetapan reference kategoriknya dan apakah pemberian code reference kategoriknya diberi code 0, atau 1 dan lainnya else… Terimakasih
Selamat pagi.. untuk penetapan kategori 0 dan 1, biasanya di asumsikan berhubungan positif dengan nilai Y (sesuai hipotesis awal penelitian). nilai 0 digunakan untuk menandakan kelompok yang “kurang berpengaruh” terhadap nilai Y, dan sebaliknya nilai 1 digunakan dengan asumsi “lebih berpengaruh terhadap nilai Y”. sebenarnya itu terserah peneliti dalam menentukannya, namun akan lebih mudah membaca jika koefisien hasil regresinya nanti positif. terima kasih
Pak mau nanya kalau variabel x saya rasio dan variabel Y saya dummy apa boleh pake analisis regresi logistik? Saya cuman punya 2 variabel
Terima kasih
Boleh.
Pak Agung , saya mau bertanya. Apakah analisis regresi logistik sama saja dengan analisis regresi logistik biner? thanku
eee gajadi pak ternyata udah ada jawabannya di comments. harus membiasakan membaca terlebih dahulu:) terima kasih atas ilmu nya!
sama.
Pak mau nanya kalau variabel x saya rasio dan variabel Y saya dummy apa boleh pake analisis regresi logistik?
Terima kasih
hi pak agung, saya punya beberapa pertanyaan:
1. saya menggunakan eviews 8, variabel y dummy dan satu variabel x saya dummy apakah bisa menggunakan regresi logistik ?
2. saya ingin tanya utk interpretasi uji hosmer pd eviews, ada prob, chi-sq(8) dan prob chi-sq(10) mana yg harus saya pakai sbgai patokan, krn jujur saya kurang mengerti utk membaca hasil uji tsb.
3. jika saya menggunakan regresi logit apakah saya harus jg melakukan uji kelayakan model ?
terima kasih atas jawabannya, ditunggu
(1) bisa. (2) semuanya dipakai karna menginterpretasikan hal yang berbeda. (3) iya, uji kelayakan model dilakukan di semua regresi. terima kasih..
Selamat siang pak mau tanya. Penelitian saya mngenai pengarruh penerapan sistem pelaporan terhadap asimetri informasi. Itu Variabel Independen nya X1 pakai dummy variabel tetapi saya ingin menambahkan variabel lain sebagai variabel kontrol yaitu X2X3 dan X4. Lantas bagaimana nnt memasukan ke SPSS nya pak apakah variabel kontrol bisa disamakan dengan variabel independen? dan nnt ketika interpretasinya apakahjuga disamakan dengan variabel independen? terimaksih
Selamat siang mbk… sy masih blm paham dengan variabel kontrol. Krn biasanya itu sy jumpai di penelitian didalam lab. Pemahaman sy dlm regresi variabel independen akan bersama sama mempengaruhi dependen, bukan bergerak sendiri sendri.
Terima kasih
Selamat pagi, pak Agung.
Maaf pak saya mau bertanya.
Saat ini saya sedang melakukan penelitian ttg “Pengaruh independensi auditir dan kualitas audit terhadap harga saham”. Dimana variabel X1 dan X2 merupakan variabel dummy. Apakah uji yg tepat utk penelitian saya tsb, pak? Sebelumnya saya sudah mencoba menguji menggunakan uji asumsi klasik. Dari hasil uji normalitas, data saya dinyatakan tdk normal. Dan dari hasil uji heterokedastisitas, data saya terkena heterokedastisitas.
Software yg saya gunakan adalah SPSS versi 22.
Mohon pencerahannya, pak. Terima kasih.
selamat sore mbak anisa,
tampaknya permasalahannya cukup rumit ya mbk.. uji normalitas dan uji hetrerokedastisitasnya tidak berjalan dengan baik. namun, saya melihat problem utama adalah bahwa skala data yang mbak gunakan semuanya adalah dummy, baik x dan y nya. saya rasa perlu dipikirkan lagi karena regresi tidak disarankan untuk skala data nominal dan ordinal. dummy hanya diperbolehkan sebagai pelengkap saja. mungkin solusinya adalah menambah variabel dengan skala rasio. Terima Kasih
siang Pak, saya mau tanya. Bagaimana perlakuan variabel dummy jika “y” nya adalah variabel dummy ? apakah variabel y tersebut mesti di transform data dulu atau bagaimana pak solusinya . Dan kira2 uji apakah yang cocok untuk menguji y tersebut pak? soalnya saya sudah pakai uji normalitas untuk menguji variabel y dummy tersebut namun tetep saja data tidak berdistibusi normal. Mohon bantuannya pak. Terima kasih
Selamat siang mbk diah.. jika variabel y nya adalah dummy, maka yang mbk maksud adalah regresi logistik atau biner. Silahkan cari artikel di blog ini tentang regresi logistik di penelusuran. Terima kasih
Selamat malam pak, saya mau nanya. Jenis data saya adalah data panel. Da n menggunakan aplikasi eviews, sdngkan yg bpa jelaskan menggunakan spss, apakah variabel dummy sndiri bisa menggunakan aplikasi eviews?
selamat pagi mas UUS. perlu mas ketahui bahwa dummy dalam regresi itu adalah teori. jadi, mestinya software yang mengikuti teori, bukan sebaliknya. meski saya blm pernah pakai eviews, tapi jika dia tidak bisa menjalankan dummy di regresi, berarti kredibilitas sebagai software statistik perlu dipertanyakan. jawabnnya: seharusnya bisa. terima kasih.
Mas, jadi yang saya tangkap, jika salah satu variabel X nya merupakan variabel dummy, cara mengolah datanya sama saja seperti variabel skala rasio lainnya? Baik variabel dummy maupun variabel berskala rasio tetap disatukan dalam satu data ketika hendak mengolah di SPSS? Hanya saja diberi keterangan nominal pada tabel measure? Atau ada tambahan lain Mas?
Yup…kurang lebih seperti itu.. hanya beda di cara intwrpretasinya.
Untuk spss biasanya settingannya di tabel measure. Klo minitab biasanya tdk ada seting label, tapi waktu proses regresinya nanti dipisahkan mana yang rasio mana yang dummy.
Terima kasih
Pak saya mau tanya, kalau penelitian 1 x dengan 5 y dan salah satunya adalah var dummy, cara pengelolahannya seperti apa ya pak? Terimakasih jawabannya
Mungkin yang dimaksud variabel x nya ada 5 dan variabel y ada satu ya? Tergantung skala nilai y nya…jika variabel y adalah biner (1 dan 2) atau dummy, maka menggunakan regresi logistik. Jika y nya rasio atau interval maka bisa gunakan regresi berganda.
Jika data nya data panel, maka bisa menggunakan regresi panel.
Terima kasih
Selamat malam pak, jenis data saya adalah data panel.. Di variabel independentnya ada variabel dummy, pertanyaan saya pak.. Kenapa variabel dummy tidak diikutsertakan dalam uji asumsi klasik? Mohon pencerahannya pak
Selamat pagi oci..
diantara keempat uji asumsi klasik (linearitas, muktikolinearitas, heteroskedasitas, dan normalitas) hanya multikolinearitas yang mungkin bisa dilakukan untuk pengujian variabel dummy di regresi. mengapa demikian?
tak lain karena regresi sendiri mensyaratkan variabel dengan skala parametrik; yakni interval dan rasio. sedangkan dummy termasuk skala nonparametrik; nominal atau ordinal.
sehingga tidak bisa diuji asumsi klasik. oci bisa baca artikel saya tentang uji asumsi klasik dan akan mengerti mngapa skala nonparametrik tdk bisa di uji linearitas dll.
itulah sebabnya mengapa kita sebaiknya jgn terlalu byk membuat dummy u variabel independennya.
terima kasih.
Pak agung, utk variabel dummy (1 atau 0) apakah tdk apa apa kalau menggunakan PLS? Krn setelah di lakukan uji chow, LM, dan hausman yang keluar adalah PLS. bagaimana caranya agar hasil dari ketiga uji tersebut berubah dari PLS jadi RE/FE..
ini bahas data panel ya? saya sebenarnya belum membahs data panel. mungkin nanti saya akan buat.
oh ya, tentang PLS, RE, FE merupakan metode yang akan digunakan untuk membahas data tersebut. jadi, tidak ada yg salah dengan ketiga metode tersebut. memang ada kekurangan dan kelebihannya. tapi jika uji chow mrngeluarkan hasil bahwa datanya sebaiknya menggunakan PLS, maka gunakanlah PLS. karna berarti data tersebut tidak berbeda antara cross section dan time seriesnya.
saya justru kuatir dengan komposisi variabrl yg mbk gunakan. ingat, data sebaiknya di dominasi oleh data parametrik, skala rasio, upayakan variabrl dummy hanya 1 dari 4 atau lima variabel rasio.
semoga mencerahkan. jika belum, silahkan mengisi form di halaman contact
selamat malam pak Agung,, apakah variabel dummy dalam regresi perlu memenuhi uji asumsi klasik?
jika yang dimaksud regresi berganda, pastinya perlu untuk memenuji uji asumsi klasik untuk mendapat hasil yang baik. maka usahakan variabel dummy hanya sedikit saja dalam regresi.
maaf pak mau bertanya, variabel bebas saya semuanya dummy dan dosen bilang jika semuanya dummy berarti tidak logistik sementara variabel terikatnya bersifat dikotomi ( ya atau tidak). mohon pencerahannya
Yang dimaksud dosen mbak adalah regresi mensyaratkan data di skala interval atau rasio. Jadi sebaiknya tambahkan satu atau 2 variabel yang bukan dummy.
Jika dipaksakan, nanti akan timbul masalah prasyarat penggunaan regresi logistik. Karna data menjadi nonparametrik yang seharusnya tdk layak diolah dengan regresi.
Terima kasih
Permisi pak.. mohon bantuannya.. saya mahasiswi semester akhir sedang mengerjakan skripsi. Variabel independen saya salah satunya menggunakan dummy, sedangkan variabel dependen saya menggunakan rasio. Benarnya menggunakan berganda atau logistik ya, pak? Terimakasih..
Regresi berganda mbk
permisi pak, saya ingin bertanya jika salah satu variable X saya menggunakan var. dummy dan variable Y saya juga menggunakan dummy , lebih baik saya menggunakan regresi logistik atau liniar ya pak? dan kebetulan saya juga menggunakan var. moderasi yg tidak menggunakan var. dummy .
mohon di jawab ya pak dan terima kasih sebelumnya
Jika y dummy, maka regresi logistik. Terima kasih
permisi pak, maaf mau bertanya. jika 4 variabel x menggunakan variabel dummy dan y menggunakan rasio, maka yg benar menggunakan regresi logistik/regresi berganda? lalu bagaimana untuk perhitungan uji normalitas dan uji asumsi klasik apakah harus digunakan juga? terimakasih.
jika variable y rasio, maka menggunakan regresi berganda. silahkan cari literatur untuk uji asumsi klasiknya. terima kasih
saya mau bertanya pak, apakah itu dimaksudkan untuk regresi logistik?
Assalamualaikum, pak.
Saya mahasiswa tingkat akhir yang sedang menyusun skripsi. Penelitian saya tentang manajemen keuangan, yang dimana profitabilitas sebagai variabel X (rasio), nilai perusahaan sebagai variabel Y (rasio), dan kebijakan dividen sebagai variabel intervening (dummy). Pada uji normalitas hasilnya tidak normal, kemudian saya transform menjadi Lg10 dan kemudian hasilnya normal (pada uji normalitas variabel dummy tidak diikut sertakan). Pertanyaan saya
1. Pada uji asumsi klasik selanjutnya (uji multiko, hetero, autokorelasi, dan linearitas) apakah variabel dummy harus ikut transformasi data juga atau tidak yah pak?
2. Apakah variabel dummy sebagai intervening ini menggunakan regresi logistik?
Terima kasih
Wa alaikum salam mbak.
1. Untuk analisis uji asumsi klasik, semuanya menggunakan data yang sama. Data itupun nanti digunakan data yang diolah regresinya. Jadi jika pada salah satu uji asumsi klasik ada eliminasi data, maka ulangi juga pada uji yang lain.
2. Tidak ada larangan menggunakan intervening dalam regresi. Tapi menurut saya agak tidak tepat. Intervening lebih cocok menggunakan analisis path atau sem. Terlebih nanti akan ada resiko munculnya multikolinear. Tetapi, tetap di poin sebelumnya, tidak ada larangan. Terima kasih